Как бы выглядела ваша модель логистической регрессии?
ПрограммированиеData science+2
Анонимный вопросData Science
· 2,6 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 25 февр 2022
Типы логистической регрессии
===========================
Логистическую регрессию можно разделить на типы в зависимости от типа классификации, которую она выполняет. С учетом этого существует 3 типа логистической регрессии :-
Бинарная логистическая регрессия
Полиномиальная логистическая регрессия
Порядковая логистическая регрессия
====================================
Бинарная логистическая регрессия
Бинарная логистическая регрессия является наиболее часто используемым типом.
В этом типе зависимая/целевая переменная имеет два разных значения: 0 или 1, злокачественное или доброкачественное,
пройдено или не пройдено, допущено или не допущено.
====================================
Пример логистической регрессии в Python
====================================
В общем, бинарная логистическая регрессия описывает взаимосвязь между зависимой бинарной переменной и одной или несколькими независимыми переменными. Бинарная зависимая переменная имеет два возможных результата:
«1» для истины/успеха; или
«0» для ложного/неудачного
Давайте теперь посмотрим, как применить логистическую регрессию в Python на практическом примере.
Шаги по применению логистической регрессии в Python
Шаг 1. Собираем данные
Чтобы начать с простого примера, предположим, что ваша цель — построить модель логистической регрессии на Python, чтобы определить, будут ли кандидаты поступать в престижный университет.Здесь есть два возможных результата: допущено (представлено значением «1») и отклонено (представлено значением «0»).
Затем вы можете построить логистическую регрессию в Python, где: Зависимая переменная показывает, принимается ли человек; а также
3 независимые переменные: балл GMAT, средний балл и количество лет опыта работы.Вот как будет выглядеть набор данных:
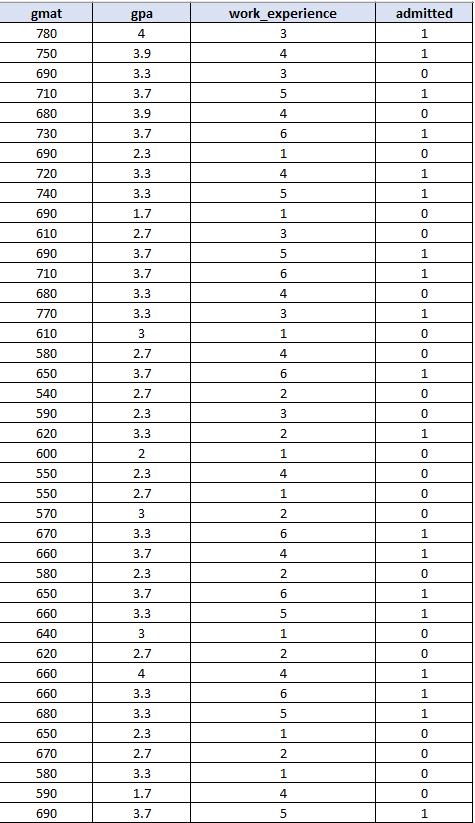
Обратите внимание, что приведенный выше набор данных содержит 40 наблюдений. На практике вам понадобится больший размер выборки, чтобы получить более точные результаты. Затем примените train_test_split. Например, вы можете установить размер теста равным 0,25, и поэтому тестирование модели будет основано на 25% набора данных, а обучение модели будет основано на 75% набора данных. Запустите код на Python, и вы получите следующую матрицу путаницы с точностью 0,8 (обратите внимание, что в зависимости от вашей версии sklearn вы можете получить разные результаты точности.
==================
Импортируйте необходимые пакеты в Python виртуальное окружение.
Прежде чем начать, убедитесь, что в Python установлены следующие пакеты:
- pandas — используется для создания DataFrame и загрузки набора данных в Python pandas dataframe .
- sklearn — используется для построения модели логистической регрессии в Python.
- seaborn - используется для создания матрицы путаницы
- matplotlib — используется для отображения диаграмм

Как видно из матрицы:
TP = Истинные положительные результаты = 4
TN = истинно отрицательные значения = 4
FP = ложные срабатывания = 1
FN = ложноотрицательные результаты = 1
Затем вы также можете получить Точность, используя:
Точность = (TP+TN)/Всего = (4+4)/10 = 0,8
=========================================
Таким образом, точность тестового набора составляет 80%.
=========================================
Погружение глубже в результаты
Давайте теперь напечатаем два компонента в коде Python:
печать (X_test)
печать (y_pred)
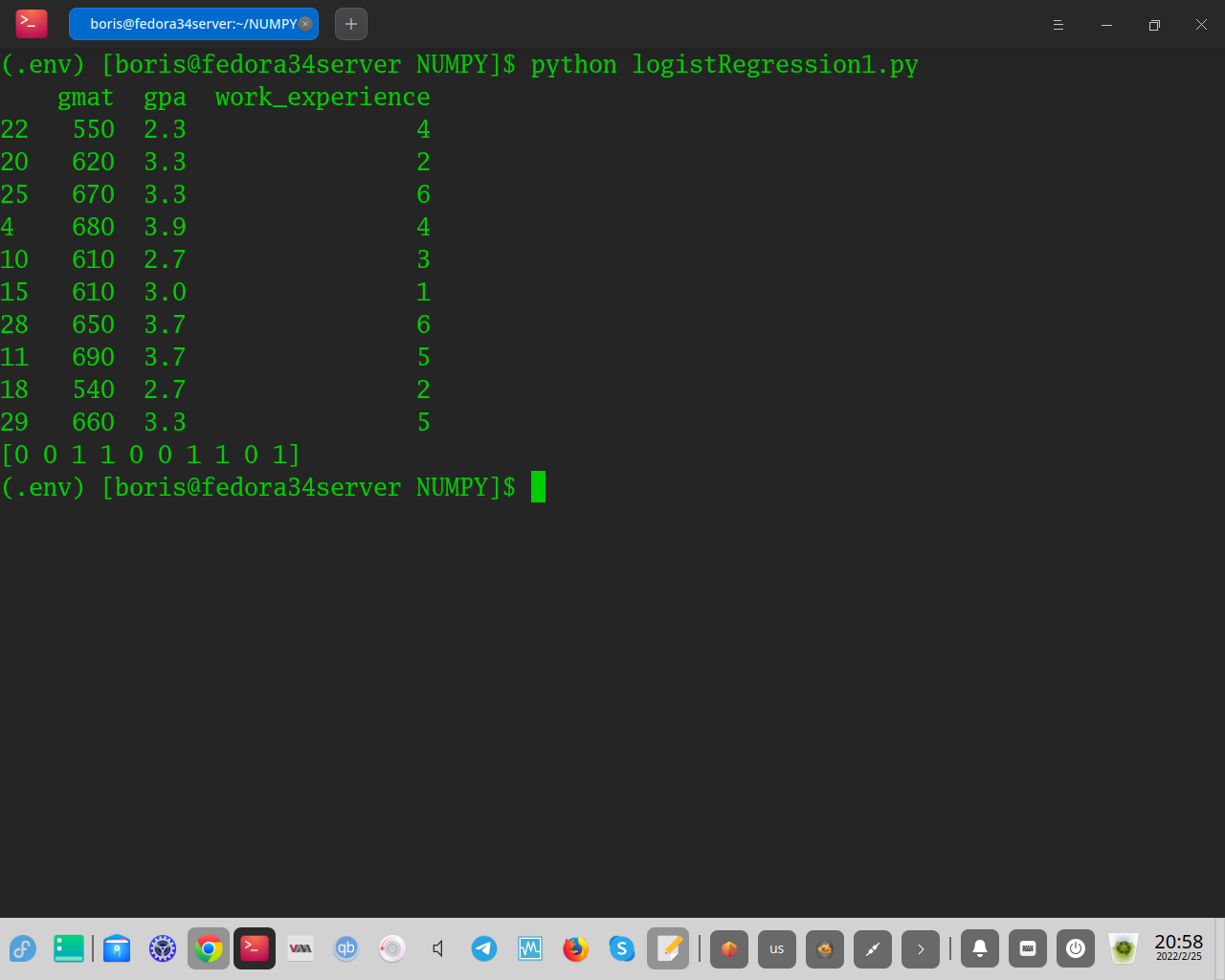
** gmat gpa work_experience
22 550 2.3 4
20 620 3.3 2
25 670 3.3 6
4 680 3.9 4
10 610 2.7 3
15 610 3.0 1
28 650 3.7 6
11 690 3.7 5
18 540 2.7 2
29 660 3.3 5
[0 0 1 1 0 0 1 1 0 1]
Напомним, что наш исходный набор данных (из шага 1) содержал 40 наблюдений. Поскольку мы установили размер теста равным 0,25, матрица путаницы отобразила результаты для 10 записей (=40*0,25). Это 10 тестовых записей:

В фактическом наборе данных (из шага 1) вы увидите, что для тестовых данных мы получили правильные результаты в 8 из 10 раз:
Это соответствует уровню точности 80%
=======================
Проверка прогноза для нового набора данных
Допустим, у вас есть новый набор данных с 5 новыми кандидатами:

Полный код для получения прогноза для 5 новых кандидатов:

** gmat gpa work_experience
0 590 2.0 3
1 740 3.7 4
2 680 3.3 6
3 610 2.3 1
4 710 3.0 5
[0 1 1 0 1]
Ожидается, что первый и четвертый кандидаты не будут допущены, а остальные кандидаты, как ожидается, будут допущены.