Что такое PCA, и чем он может помочь?
ПрограммированиеData science+3
Алена КаменецкихData Science
· 4,8 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 17 нояб 2021
Что такое анализ главных компонентов?
Анализ главных компонентов, или PCA, - это метод уменьшения размерности, который часто используется для уменьшения размерности больших наборов данных путем преобразования большого набора переменных в меньший, который по-прежнему содержит большую часть информации в большом наборе. Уменьшение количества переменных в наборе данных, естественно, происходит за счет точности, но хитрость в уменьшении размерности заключается в том, чтобы торговать небольшой точностью ради простоты. Поскольку меньшие наборы данных легче исследовать и визуализировать, а анализ данных становится намного проще и быстрее для алгоритмов машинного обучения без обработки посторонних переменных.
Подводя итог, можно сказать, что идея PCA проста - уменьшить количество переменных в наборе данных, сохранив при этом как можно больше информации.
ШАГ 1: СТАНДАРТИЗАЦИЯ
Цель этого шага - стандартизировать диапазон непрерывных исходных переменных, чтобы каждая из них вносила равный вклад в анализ.
В частности, причина того, почему так важно выполнить стандартизацию до PCA, заключается в том, что последний очень чувствителен к вариациям исходных переменных. То есть, если есть большие различия между диапазонами исходных переменных, те переменные с большими диапазонами будут преобладать над переменными с небольшими диапазонами (например, переменная, которая находится в диапазоне от 0 до 100, будет преобладать над переменной, которая находится в диапазоне от 0 до 1. ), что приведет к необъективным результатам. Таким образом, преобразование данных в сопоставимые масштабы может предотвратить эту проблему.
Математически это можно сделать путем вычитания среднего и деления на стандартное отклонение для каждого значения каждой переменной.
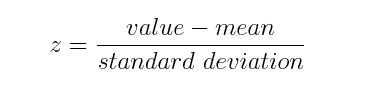
После завершения стандартизации все переменные будут преобразованы в один масштаб.
ШАГ 2: РАСЧЕТ КОВАРИАНТНОЙ МАТРИЦЫ
Цель этого шага - понять, как переменные набора входных данных отличаются от среднего по отношению друг к другу, или, другими словами, увидеть, есть ли между ними какая-либо связь. Потому что иногда переменные сильно коррелированы и содержат избыточную информацию. Итак, чтобы идентифицировать эти корреляции, мы вычисляем ковариационную матрицу. Ковариационная матрица представляет собой симметричную матрицу размера p × p (где p - количество измерений), в которой в качестве элементов записаны ковариации, связанные со всеми возможными парами исходных переменных. Например, для 3-мерного набора данных с 3 переменными x, y и z ковариационная матрица представляет собой матрицу 3 × 3 из:
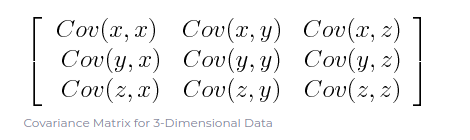
Поскольку ковариация переменной с самой собой - это ее дисперсия (Cov (a, a) = Var (a)), на главной диагонали (сверху слева направо снизу) у нас фактически есть дисперсии каждой исходной переменной. А поскольку ковариация коммутативна (Cov (a, b) = Cov (b, a)), элементы ковариационной матрицы симметричны относительно главной диагонали, что означает, что верхняя и нижняя треугольные части равны.

Что ковариации, которые мы имеем в качестве элементов матрицы, говорят нам о корреляциях между переменными? если положительный, то: две переменные увеличиваются или уменьшаются вместе (коррелировано) если отрицательный, то: один увеличивается, когда другой уменьшается (обратно коррелирован). Теперь, когда мы знаем, что ковариационная матрица - это не более чем таблица, которая суммирует корреляции между всеми возможными парами переменных, давайте перейдем к следующему шагу.
ШАГ 3: ВЫЧИСЛЕНИЕ СОБСТВЕННЫХ ВЕКТОРОВ И СОБСТВЕННЫХ ЗНАЧЕНИЙ МАТРИЦЫ КОВАРИАНТНОСТИ ДЛЯ ИДЕНТИФИКАЦИИ ОСНОВНЫХ КОМПОНЕНТОВ
Собственные векторы и собственные значения - это понятия линейной алгебры, которые нам нужно вычислить из ковариационной матрицы, чтобы определить главные компоненты данных. Прежде чем перейти к объяснению этих концепций, давайте сначала поймем, что мы подразумеваем под основными компонентами. Основные компоненты - это новые переменные, которые построены как линейные комбинации или смеси исходных переменных. Эти комбинации выполняются таким образом, что новые переменные (то есть главные компоненты) не коррелированы, и большая часть информации в исходных переменных сжимается или сжимается в первых компонентах. Итак, идея состоит в том, что 10-мерные данные дают вам 10 основных компонентов, но PCA пытается поместить максимум возможной информации в первый компонент, затем максимум оставшейся информации во второй и так далее, пока не появится что-то вроде того, что показано на графике ниже.

Такая организация информации в основных компонентах позволит вам уменьшить размерность без потери большого количества информации, и это за счет отбрасывания компонентов с низкой информацией и рассмотрения оставшихся компонентов как ваших новых переменных.
Здесь важно понимать, что главные компоненты менее интерпретируемы и не имеют никакого реального значения, поскольку они построены как линейные комбинации исходных переменных.
С геометрической точки зрения, главные компоненты представляют собой направления данных, которые объясняют максимальное количество отклонений, то есть линии, которые захватывают большую часть информации о данных. Связь между дисперсией и информацией здесь заключается в том, что чем больше дисперсия, переносимая линией, тем больше дисперсия точек данных вдоль нее, и чем больше дисперсия вдоль линии, тем больше информации она содержит. Проще говоря, просто думайте о главных компонентах как о новых осях, которые обеспечивают лучший угол для просмотра и оценки данных, чтобы различия между наблюдениями были лучше видны.
Как PCA конструирует основные компоненты
Поскольку существует столько главных компонентов, сколько переменных в данных, главные компоненты строятся таким образом, что первый главный компонент учитывает максимально возможную дисперсию в наборе данных. Например, предположим, что диаграмма рассеяния нашего набора данных выглядит так, как показано ниже. Можем ли мы угадать первый главный компонент? Да, это примерно линия, которая соответствует фиолетовым отметкам, потому что она проходит через начало координат, и это линия, на которой проекция точек (красные точки) является наиболее разбросанной. Или, говоря математически, это линия, которая максимизирует дисперсию (среднее квадратов расстояний от проецируемых точек (красные точки) до начала координат).
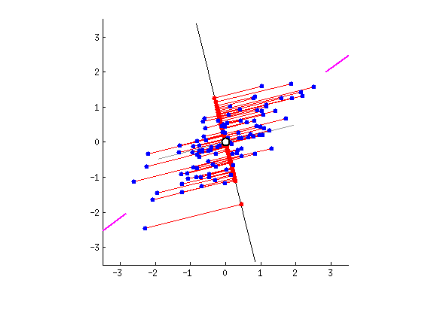
Это продолжается до тех пор, пока не будет вычислено общее количество p главных компонентов, равное исходному количеству переменных. Теперь, когда мы поняли, что мы подразумеваем под главными компонентами, давайте вернемся к собственным векторам и собственным значениям. Прежде всего вам нужно знать о них, так это то, что они всегда входят парами, так что каждый собственный вектор имеет собственное значение. И их количество равно количеству измерений данных. Например, для трехмерного набора данных есть 3 переменных, следовательно, есть 3 собственных вектора с 3 соответствующими собственными значениями.
Без лишних слов, за процедурой описанной выше, стоят собственные векторы и собственные значения, потому что собственные векторы матрицы ковариации на самом деле являются направлениями осей, где наблюдается наибольшая дисперсия (большая часть информации) и которые мы называем главными компонентами. А собственные значения - это просто коэффициенты, прикрепленные к собственным векторам, которые дают величину дисперсии, переносимую в каждом основном компоненте.
Ранжируя собственные векторы в порядке их собственных значений, от наибольшего к наименьшему, вы получаете главные компоненты в порядке значимости.
Это преобразование данных, которое позволяет максимально уменьшить размерность данных, сохранив при этом как можно больше полезной информации. В анализе данных это очень полезное преобразование, представьте, что у вас есть много (порядка сотен или тысяч) признаков, причем какие-то из них линейно зависят друг от друга, соответственно уникальной информации не сожержат... Читать далее