Какие атрибуты необходимы для функции активации в нейронной сети?
ПрограммированиеМашинное обучение+3
Алена КаменецкихМашинное обучение и Нейронные сети
· 2,4 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 17 февр 2022
Функции активации — это математические уравнения, определяющие выходные данные модели нейронной сети. Функции активации также оказывают большое влияние на способность нейронной сети сходиться и скорость сходимости, а в некоторых случаях функции активации могут вообще препятствовать сходимости нейронных сетей. Функция активации также помогает нормализовать вывод любого входа в диапазоне от 1 до -1 или от 0 до 1.
Функция активации должна быть эффективной и сокращать время вычислений, поскольку нейронная сеть иногда обучается на миллионах точек данных.
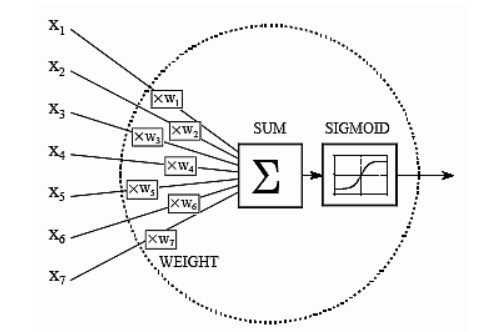
Вот вывод-
Y = ∑ (веса * вход + смещение)
и может варьироваться от -бесконечности до +бесконечности. Поэтому необходимо ограничить вывод, чтобы получить желаемый прогноз или обобщенные результаты.
Y = функция активации (∑ (веса * вход + смещение))
Таким образом, функция активации является важной частью искусственной нейронной сети. Они решают, должен ли нейрон быть активирован или нет, и это нелинейное преобразование, которое можно выполнить на входе, прежде чем отправить его на следующий слой нейронов или завершить вывод.
Свойства функций активации
Нелинейность
Непрерывно дифференцируемы
Спектр
Монотонность
Приближает идентичность рядом с источником
=================================
Нелинейные функции активации
Современные модели нейронных сетей используют нелинейные функции активации. Они позволяют модели создавать сложные сопоставления между входами и выходами сети, такими как изображения, видео, аудио и наборы данных, которые являются нелинейными или имеют высокую размерность.
====================================
В основном существует 3 типа функций нелинейной активации.
====================================
Сигмовидные функции активации
Выпрямленные линейные единицы или ReLU
Сложные нелинейные функции активации
======================================
Сигмовидные функции активации
Сигмовидные функции — это ограниченные, дифференцируемые, действительные функции, которые определены для всех действительных входных значений и имеют неотрицательную производную в точке e.

Выход функции активации всегда будет находиться в диапазоне (0,1) по сравнению с (-inf, inf) линейной функции. Он нелинейный, непрерывно дифференцируемый, монотонный и имеет фиксированный выходной диапазон. Но он не центрирован на нуле.
===================================
Гиперболический тангенс
Функция производит выходные данные в масштабе [-1, 1] и является непрерывной функцией. Другими словами, функция производит вывод для каждого значения x.

Проблемы с сигмовидными функциями активации
Проблема исчезающих градиентов
Основная проблема с глубокими нейронными сетями заключается в том, что градиент резко уменьшается по мере того, как он распространяется по сети в обратном направлении. Ошибка может быть настолько мала к тому времени, когда она достигает слоев, близких к входным данным модели, что она может иметь очень незначительный эффект. Таким образом, эта проблема называется проблемой «исчезающих градиентов».
=============================
Выпрямленные линейные единицы или ReLU
Сигмовидную и гиперболическую тангенсные функции активации нельзя использовать в сетях со многими слоями из-за проблемы исчезающего градиента. Выпрямленная линейная функция активации решает проблему исчезающего градиента, позволяя моделям быстрее обучаться и работать лучше.
Исправленная линейная активация является активацией по умолчанию при разработке многослойного персептрона и сверточных нейронных сетей.
Выпрямленные линейные единицы (ReLU)
ReLU — наиболее часто используемая функция активации в нейронных сетях. Математическое уравнение для ReLU:
ReLU(x) = макс(0,x)
Таким образом, если вход отрицательный, выход ReLU равен 0, а для положительных значений это x.

Хотя это выглядит как линейная функция, это не так. ReLU имеет производную функцию и допускает обратное распространение.
Есть одна проблема с ReLU. Предположим, что большинство входных значений отрицательны или равны 0, ReLU выдает на выходе 0, а нейронная сеть не может выполнить обратное распространение. Это называется проблемой Dying ReLU. Кроме того, ReLU — неограниченная функция, что означает отсутствие максимального значения.
=======================================
Плюсы:
Меньшая временная и пространственная сложность
Избегает проблемы исчезающего градиента.
Минусы:
Представляет проблему мертвого релу.
Не позволяет избежать проблемы взрывающегося градиента.
=======================================
Экспоненциальная линейная единица (ELU)
ELU ускоряет обучение в нейронных сетях и приводит к более высокой точности классификации, а также решает проблему исчезающего градиента. ELU имеют улучшенные характеристики обучения по сравнению с другими функциями активации. ELU имеют отрицательные значения, которые позволяют им приближать средние активизации единиц к нулю, как при пакетной нормализации, но с меньшей вычислительной сложностью.
Математическое выражение для ELU:
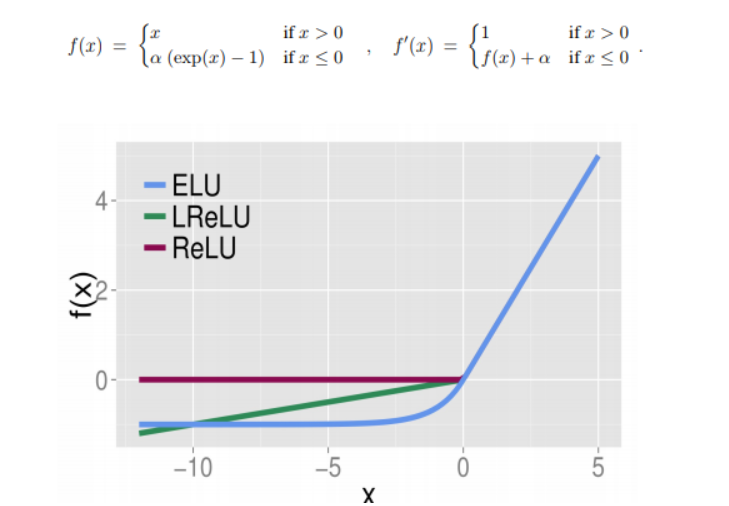
ELU разработан, чтобы объединить хорошие части ReLU и дырявого ReLU, и у него нет проблемы умирающего ReLU. он насыщается для больших отрицательных значений, что позволяет им быть практически неактивными.
=====================================
Масштабированная экспоненциальная линейная единица (SELU)
SELU включает нормализацию, основанную на центральной предельной теореме. SELU — это монотонно возрастающая функция, которая имеет приблизительно постоянный отрицательный результат при большом отрицательном входе. SELU чаще всего используются в самонормирующихся сетях (SNN). ELU разработан, чтобы объединить хорошие части ReLU и дырявого ReLU, и у него нет проблемы умирающего ReLU. он насыщается для больших отрицательных значений, что позволяет им быть практически неактивными.

Выходные данные SELU нормализованы, что можно назвать внутренней нормализацией, поэтому все выходные данные имеют среднее значение, равное нулю, и стандартное отклонение, равное единице. Основное преимущество SELU заключается в том, что проблема исчезающего и взрывающегося градиента невозможна, и, поскольку это новая функция активации, она требует дополнительного тестирования перед использованием.
====================================
Софтплюс или SmoothReLU
Производной функции softplus является логистическая функция.
Математическое выражение

======================================
Функция Swish
Функция Swish была разработана Google и обладает превосходной производительностью при том же уровне вычислительной эффективности, что и функция ReLU. ReLU по-прежнему играет важную роль в исследованиях глубокого обучения даже сегодня.
Но эксперименты показывают, что эта новая функция активации превосходит ReLU для более глубоких сетей. Математическое выражение для функции Swish:

Выше мы попытались объяснить некоторые нелинейные функции активации с помощью математических выражений
2 эксперта согласны
Виктор Зосимов
17 февраля 2022подтверждает
Это правильно