Как бы вы инициализировали веса нейронной сети?
Машинное обучениеИсследования+2
Анонимный вопросМашинное обучение и Нейронные сети
· 2,2 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 19 февр 2022
Инициализация веса является важным фактором при разработке модели нейронной сети. Узлы в нейронных сетях состоят из параметров, называемых весами, которые используются для вычисления взвешенной суммы входных данных.
Модели нейронных сетей подгоняются с использованием алгоритма оптимизации, называемого стохастическим градиентным спуском, который постепенно изменяет веса сети, чтобы минимизировать функцию потерь, что, как мы надеемся, приводит к набору весов для режима, который способен делать полезные прогнозы. Этот алгоритм оптимизации требует начальной точки в пространстве возможных значений веса, с которой можно начать процесс оптимизации.
============================
Инициализация весов — это процедура установки весов нейронной сети на небольшие случайные значения, которые определяют отправную точку для оптимизации (обучения или обучения) модели нейронной сети.
Обучение глубоких моделей — достаточно сложная задача, и на большинство алгоритмов сильно влияет выбор инициализации. Начальная точка может определить, сходится ли алгоритм вообще, при этом некоторые начальные точки настолько нестабильны, что алгоритм сталкивается с численными трудностями и вообще не работает.Каждый раз нейронная сеть инициализируется с другим набором весов, что приводит к другой начальной точке для процесса оптимизации и, возможно, к другому конечному набору весов с разными характеристиками производительности.
Мы не можем инициализировать все веса значением 0,0, поскольку алгоритм оптимизации приводит к некоторой асимметрии в градиенте ошибок, чтобы начать поиск эффективно.
Зачем инициализировать нейронную сеть со случайными весами?
Исторически сложилось так, что инициализация веса следует простой эвристике, такой как:
Небольшие случайные значения в диапазоне [-0,3, 0,3]
Небольшие случайные значения в диапазоне [0, 1]
Небольшие случайные значения в диапазоне [-1, 1]
В целом эти эвристики продолжают хорошо работать.
Мы почти всегда инициализируем все веса в модели значениями, взятыми случайным образом из гауссовского или равномерного распределения. Выбор гауссовского или равномерного распределения, по-видимому, не имеет большого значения, но всесторонне не изучался. Однако масштаб начального распределения оказывает большое влияние как на результат процедуры оптимизации, так и на способность сети к обобщению.
Тем не менее, за последнее десятилетие были разработаны более специализированные подходы, которые стали стандартом де-факто, поскольку они могут привести к несколько более эффективному процессу оптимизации (обучения модели).
Эти современные методы инициализации веса разделены в зависимости от типа функции активации, используемой в инициализируемых узлах, таких как «Sigmoid and Tanh» и «ReLU».
================================
Далее давайте подробнее рассмотрим эти современные эвристики инициализации весов для узлов с функциями активации Sigmoid и Tanh.
================================
Текущий стандартный подход к инициализации весов слоев и узлов нейронной сети, использующих функцию активации Sigmoid или TanH, называется инициализацией «glorot» или «xavier».
Он назван в честь Ксавьера Глорота, в настоящее время научного сотрудника Google DeepMind, и был описан в статье 2010 года Ксавьера и Йошуа Бенжио под названием «Понимание сложности обучения нейронных сетей с глубокой прямой связью». Существует две версии этого метода инициализации веса, которые мы будем называть «xavier» и «normalized xavier».
================================
Инициализация нормализованного веса Ксавьера
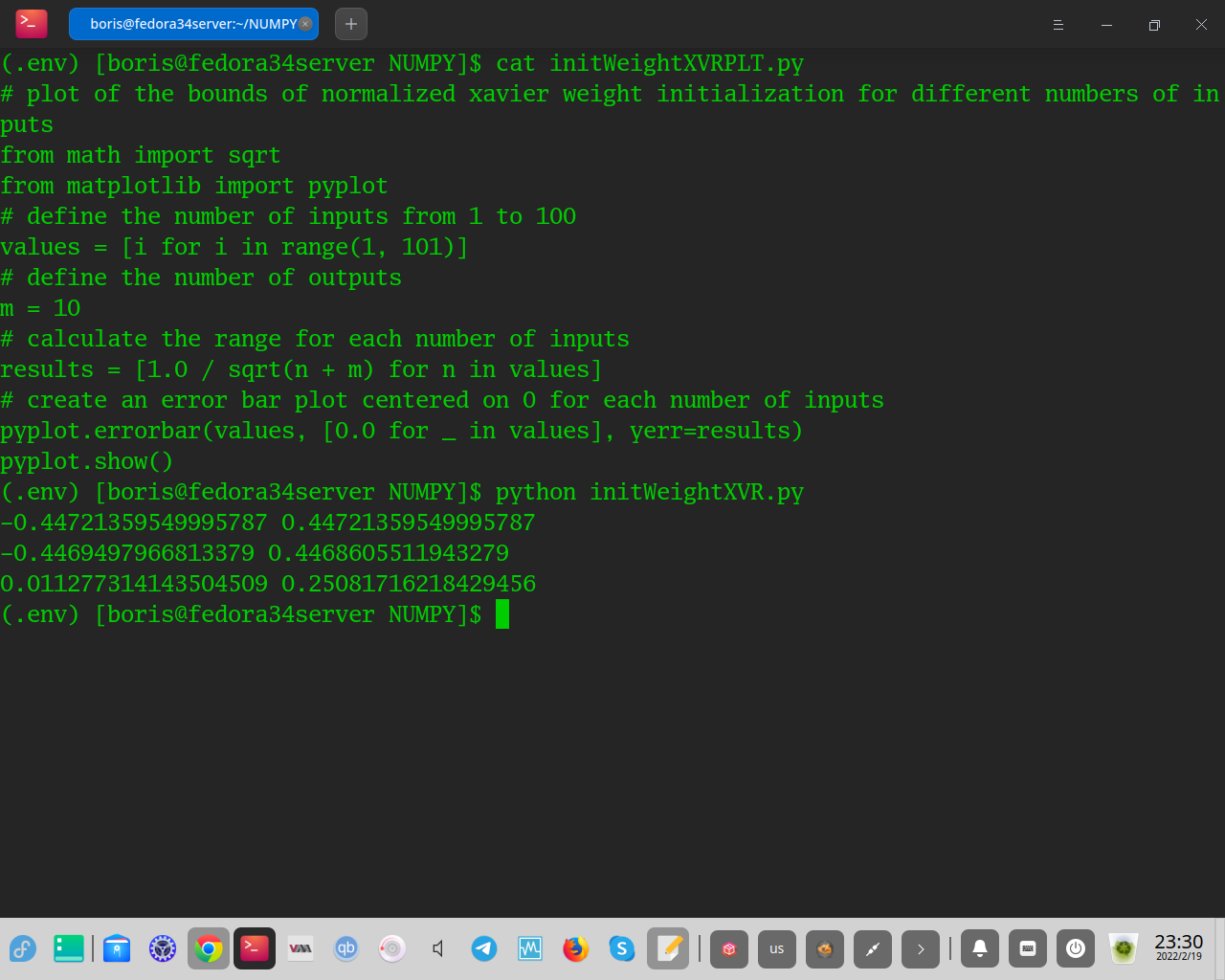
Нормализованный метод инициализации Ксавье вычисляется как случайное число с равномерным распределением вероятностей (U)
между диапазоном -(sqrt(6)/sqrt(n + m)) и sqrt(6)/sqrt(n + m),
где n — количество входов в узел (например, количество узлов в предыдущем слое), а m — количество выходов из уровня (например, количество узлов в текущем слое).
Wight = U[-(sqrt(6)/sqrt(n + m)), sqrt(6)/sqrt(n + m)]
При выполнении примера создаются веса и распечатываются сводные статистические данные.
Мы видим, что границы значений веса составляют около -0,447 и 0,447. Эти границы станут шире при меньшем количестве входных данных и более узкими при большем количестве входных данных.Мы видим, что сгенерированные веса соответствуют этим границам и что среднее значение веса близко к нулю со стандартным отклонением, близким к 0,17.
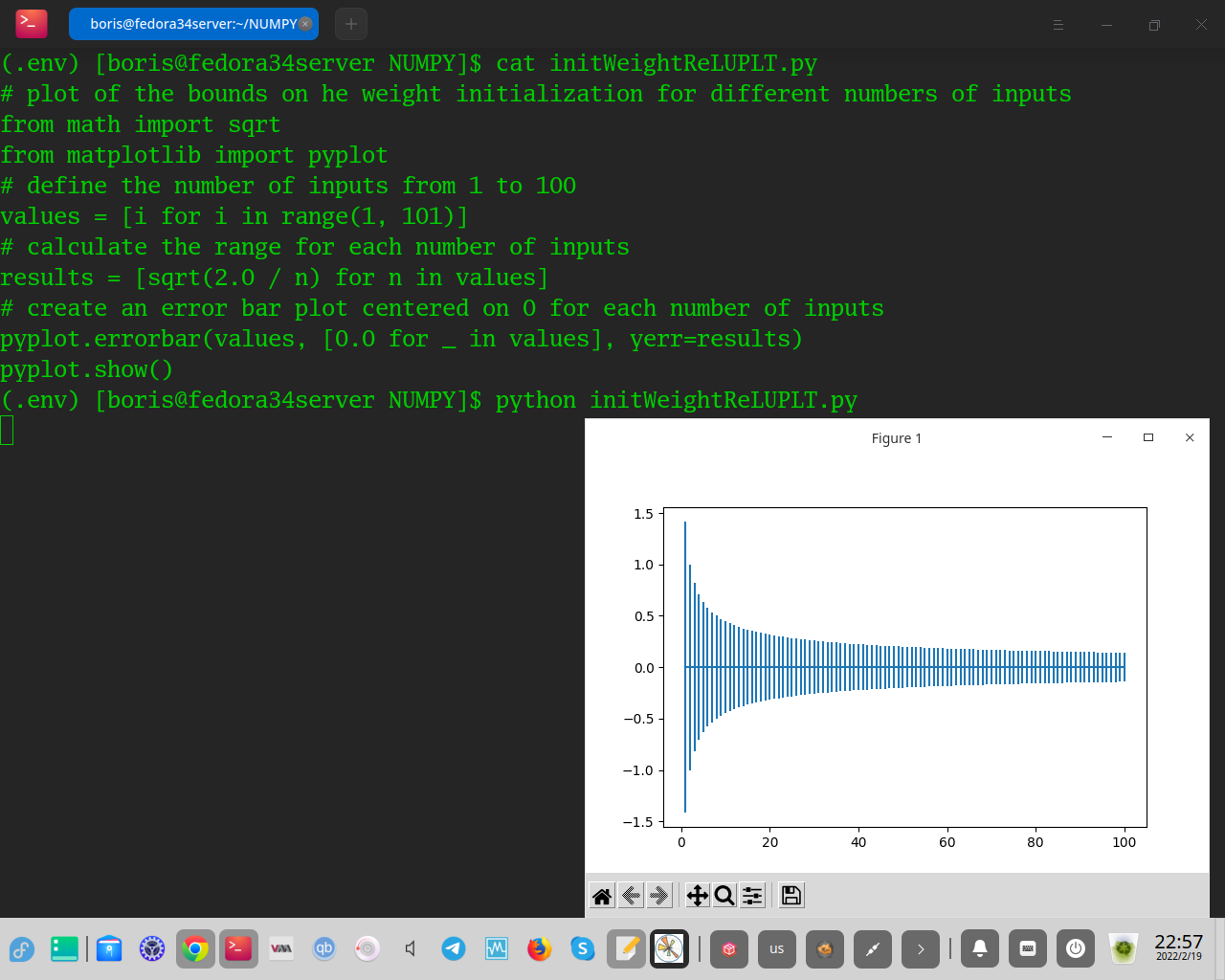
Попробуем увидеть, как разброс весов меняется в зависимости от количества входных данных.
Для этого мы можем вычислить границы инициализации веса с различным количеством входных данных от 1 до 100 и фиксированным числом 10 выходных данных и построить результат.
При выполнении следующего примера создается график, который позволяет нам сравнивать диапазон весов с различным количеством входных значений. Мы можем видеть, что диапазон начинается примерно от -0,3 до 0,3 с небольшим количеством входных данных и уменьшается примерно до -0,1 до 0,1 по мере увеличения количества входных данных. Полный пример приведен ниже.

=============================
Инициализация веса для ReLU
=============================
Было обнаружено, что инициализация веса «xavier» имеет проблемы при использовании для инициализации сетей, использующих выпрямленную линейную (ReLU) функцию активации.
Таким образом, модифицированная версия подхода была разработана специально для узлов и слоев, использующих активацию ReLU, популярную в скрытых слоях большинства многослойных моделей Perceptron и сверточных нейронных сетей. Текущий стандартный подход к инициализации весов слоев и узлов нейронной сети, использующий выпрямленную линейную (ReLU) функцию активации, называется инициализацией «he». Он назван в честь Кайминга Хэ, в настоящее время научного сотрудника Facebook, и был описан в статье 2015 года Кайминг Хэ и др. под названием «Углубление в выпрямители: превосходство на уровне человека в классификации ImageNet».
"HE" Инициализация веса .
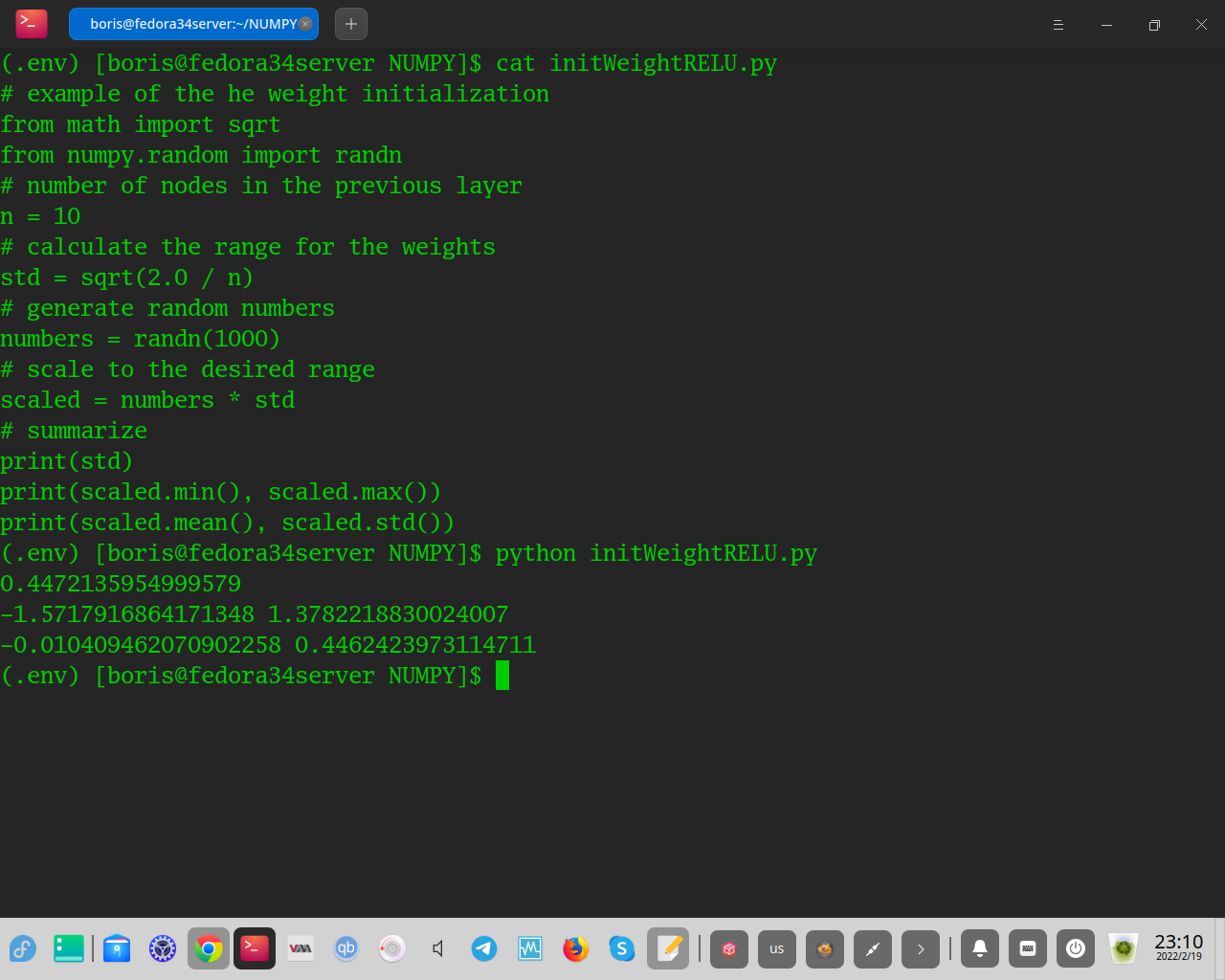
Метод инициализации вычисляется как случайное число с гауссовым распределением вероятностей (G) со средним значением 0,0 и cтандартным отклонением sqrt(2/n), где n — количество входов в узел.
Weight = G (0,0, sqrt (2/n))
Мы можем реализовать это прямо в Python.
В приведенном ниже примере предполагается 10 входных данных для узла, затем вычисляется стандартное отклонение распределения Гаусса и вычисляется 1000 начальных значений веса, которые можно использовать для узлов в слое или сети, использующей функцию активации ReLU. После расчета весов вычисленное стандартное отклонение распечатывается вместе с минимальным, максимальным, средним значением и стандартным отклонением сгенерированных весов.
============================
При выполнении примера создаются веса и распечатываются сводные статистические данные. Мы видим, что граница рассчитанного стандартного отклонения весов составляет около 0,447. Это стандартное отклонение будет увеличиваться при меньшем количестве входных данных и меньше при большем количестве входных данных.
Мы видим, что диапазон весов составляет от -1,573 до 1,433, что близко к теоретическому диапазону от -1,788 до 1,788, что в четыре раза превышает стандартное отклонение, охватывая 99,7% наблюдений в распределении Гаусса. Мы также можем видеть, что среднее значение и стандартное отклонение сгенерированных весов близки к заданным значениям 0,0 и 0,447 соответственно.
Это также может помочь увидеть, как разброс весов меняется в зависимости от количества входных данных.Для этого мы можем вычислить границы инициализации веса с различным количеством входных данных от 1 до 100 и построить результат.
=============================
При выполнении следующего примера создается график, который позволяет нам сравнивать диапазон весов с различным количеством входных значений. Мы видим, что при очень небольшом количестве входных данных диапазон велик, около -1,5 и 1,5 или от -1,0 до -1,0. Затем мы видим, что наш диапазон быстро падает примерно с 20 весов до примерно -0,1 и 0,1, где он остается достаточно постоянным.