Какие гиперпараметры вы бы стали настраивать для борьбы с переобучением у градиентного бустинга?
ПрограммированиеМашинное обучение+2
Анонимный вопросМашинное обучение и Нейронные сети
· 6,5 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 14 мар 2022
Гиперпараметр XGBoost очень хорошо настраивает Python и R
=========================
XGBoost обычно лидирует в соревнованиях по науке о данных. В этом посте я расскажу о ключевых гиперпараметрах, которые можно настроить для этого удивительного алгоритма. Неотъемлемой частью процесса обучения модели XgBoost является настройка гиперпараметров XgBoost, и мы можем сказать, что это самая важная часть. Процесс обучения XgBoost делится на два основных этапа:
=========================
Подгонка модели к данным
Настройка гиперпараметра xgboost
Стоит отметить, что процесс настройки гиперпараметров XgBoost
самая важная часть процесса обучения для этого алгоритма, и это также самая сложная часть.
=========================
Настройка гиперпараметров XGboost
XgBoost — это продвинутый алгоритм машинного обучения, обладающий огромной мощностью, а термин xgboost означает экстремальное повышение градиента. Если вы разрабатываете модель машинного обучения для ваших данных, чтобы что-то предсказывать, а производительность испробованных вами моделей вас не удовлетворяет, тогда XgBoost ключ, так как он содержит множество гиперпараметров, которые помогут вам преодолеть как переоснащение, так и недообучение.
==========================
Почему сложно настроить гиперпараметр XgBoost?
Модель XgBoost имеет много гиперпараметров, эти гиперпараметры контролируют процесс обучения и если вы правильно выберете значения для этих гиперпараметров, то у вас будет отличный шанс получить твердую модель, которая хорошо соответствует вашим данным.

Что такое xgboost?
Термин xgboost означает экстремальное повышение градиента, поэтому из названия вы можете понять, что этот алгоритм является усовершенствованной формой алгоритма повышения градиента.
поэтому, прежде чем мы углубимся в настройку гиперпараметров xgboost,
======================================
Что такое повышение градиента (GBM)?
=======================================
Бустирование — это последовательная методика, работающая по принципу ансамбля. Он сочетает в себе набор слабых учеников и обеспечивает повышенную точность прогнозирования, правильно предсказанным результатам присваивается меньший вес, а тем, которые не классифицированы, присваивается больший вес. Алгоритмы повышения, такие как xgboost, играют решающую роль в поиске компромисса между смещением и дисперсией, вот почему он считается более эффективным, чем алгоритмы бэггинга.
В оригинале -
Boosting algorithms like xgboost play a crucial role in dealing with bias-variance trade-offs, which is why it is considered to be more effective than bagging algorithms.
============================
Зачем беспокоиться о настройке гиперпараметров xgboost?
Преимущества использования xgboost в качестве модели машинного обучения огромны.
============================
Regularization: в отличие от других моделей машинного обучения, этот алгоритм помогает уменьшить переобучение, поскольку алгоритм использует регуляризацию в процессе обучения.
И вы можете управлять регуляризацией в xgboost как ручной шаг настройки гиперпараметров xgboost, используя два гиперпараметра: лямбда и альфа, мы классифицируем их оба как параметры бустера, как мы обсудим позже.
============================
Parallel processing: xgboost реализует параллельную обработку, поэтому она быстрее, чем другие алгоритмы повышения, но, с другой стороны, как мы упоминали ранее, это тип алгоритма повышения, который является последовательным алгоритмом, так как же он распараллеливается?
Он выполняет распараллеливание ВНУТРИ одного дерева, используя openMP для независимого создания ветвей.
А с точки зрения настройки гиперпараметра xgboost вы можете управлять распараллеливанием с помощью гиперпараметра nthread, который представляет собой количество параллельных потоков, используемых для запуска XGBoost.
===========================
High flexibility: благодаря большому количеству гиперпараметров,
xgboost предлагает вам безграничные возможности для настройки, оптимизации целей и критериев оценки.
===========================
Handling Missing Values: он может сам обрабатывать пропущенные значения, По мере того, как он пробует разные вещи, поскольку он сталкивается с пропущенным значением на каждом узле и узнает, какой путь выбрать для пропущенных значений в будущем.
============================
Continue on Existing Model: ее можно обучить на последней итерации, выполненной в предыдущем запуске.
============================
Cross-validation: алгоритм позволяет пользователям использовать перекрестную проверку на каждой итерации процесса повышения,
следовательно, поможет вам получить максимально возможное количество итераций повышения.
=============================
Общая парадигма «повышения» градиентного спуска разработана для аддитивных расширений любого критерия подгонки.
Джером Х. Фридман
=============================
Гиперпараметры Xgboost
Как я уже говорил вам ранее, xgboost имеет много гиперпараметров, и это может привести к жесткой настройке гиперпараметров xgboost,
Знание этих гиперпараметров необходимо для оптимального использования алгоритма xgboost. Но прежде чем углубляться в то, что это за параметры, я бы предпочел рассказать вам о категоризации этих параметров.
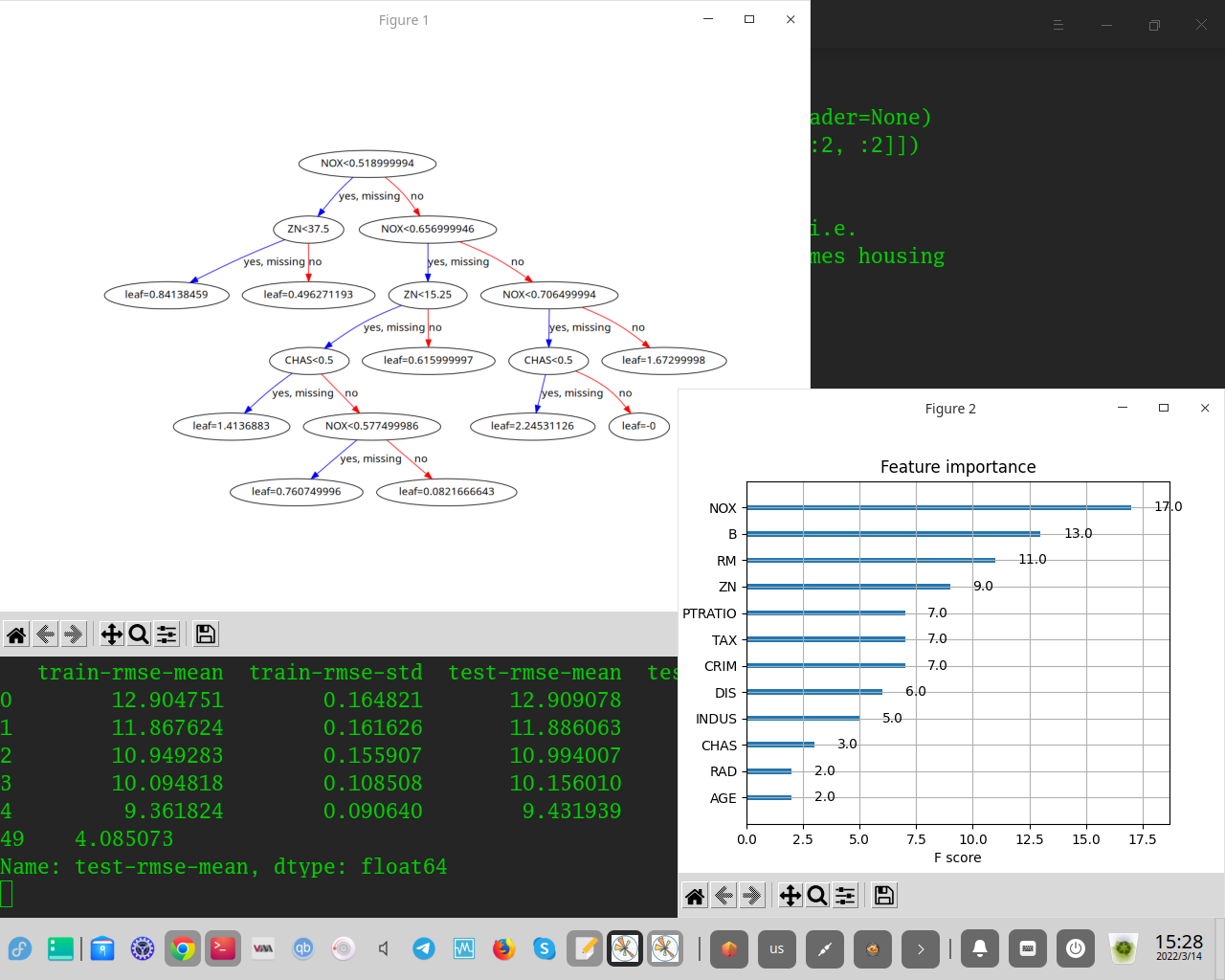
Категории гиперпараметров Xgboost
==============================
1.Общие параметры: эти параметры определяют общее функционирование модели XGBoost.
2.Параметры бустеров: управляйте отдельным бустером на каждом этапе, есть 2 типа бустеров - бустер дерева и линейный бустер.
3.Параметры задачи обучения. Эти параметры будут использоваться для определения цели оптимизации, а метрика будет рассчитываться на каждом этапе.
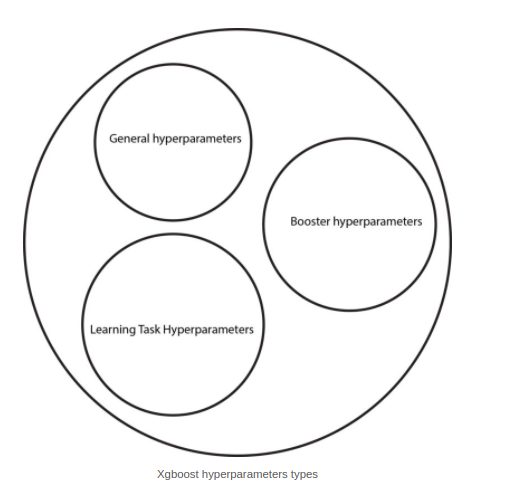
Общие гиперпараметры Xgboost:
Это параметры для руководства и управления общими функциями алгоритма xgboost, именно поэтому мы называем их общими, так как они не относятся ни к категории бустинга, ни к категории обучения.
но они направляют их обоих, и эти параметры таковы:
==========================
Booster : этот параметр помогает нам выбрать, какой бустер мы собираемся использовать:
Gbtree: оптимизатор по умолчанию, использующий древовидную модель.
Dart: как и gbtree, использует древовидную модель.
Gblinear: использует линейную модель
Обратите внимание, что ускорители древовидной модели работают лучше, чем линейная модель.
==========================
Verbosity: этот параметр как раз о том, печатать сообщения или нет, и какие сообщения:
0: Без звука
1: предупреждение по умолчанию
2: информация
==========================
Отлаживать
Nthread: вы будете использовать этот гиперпараметр xgboost для управления количеством параллельных потоков обработки.
и сколько ядер в системе должна включать система в процесс обучения, по умолчанию система задействует все ядра так
если вы хотите использовать все ядра для работы, ничего не вводите.
Параметры настройки гиперпараметра Xgboost (параметры бустера)
Как мы упоминали во введении о гиперпараметрах, есть два типа бустеров. Одна из них представляет собой древовидную модель, а другая — линейную модель и что древовидная модель превосходит линейную модель, поэтому сейчас в этой статье мы сосредоточимся на гиперпараметрах бустера древовидной модели:
===========================
Eta: этот параметр представляет скорость обучения, использование более низкой скорости поможет вам избежать переобучения, поскольку шаг модели на каждой отдельной итерации будет настолько мал, что мы сможем получить оптимальный результат с наименьшими возможными потерями.
Значение по умолчанию – 0,3.
Диапазон, который позволяет использовать алгоритм, составляет от 0 до 1, например, 0,1, 0,74, 0,5 и т. д.
==============================
Gamma: вы будете использовать этот параметр, чтобы указать минимальное снижение потерь, необходимое для разделения,
результирующее разделение узлов дает положительное снижение функции потерь. Вы должны настроить его, так как чем выше гамма, тем более консервативным будет алгоритм.
Значение по умолчанию – 0.
Диапазон значений от 0 до положительной бесконечности
===========================
Max_Deapth: этот параметр представляет собой допустимую максимальную глубину дерева, которая помогает контролировать переобучение и его необходимо настроить, поскольку настройка является неотъемлемой частью настройки гиперпараметра xgboost,
увеличение значений сделает модель более сложной и позволит обнаруживать и изучать очень специфические отношения.
Значение по умолчанию – 6.
Рекомендуемый диапазон значений от 3 до 10
===========================
Alpha: как обсуждалось ранее, представляет собой регуляризацию L1, которую можно использовать при обучении на многомерных данных.
чтобы алгоритм работал быстрее (регрессия Лассо). Увеличение этого значения сделает модель более консервативной.
Lambda: как обсуждалось ранее, она представляет собой регуляризацию L2, она, в основном используется для обработки переобучения (регрессия гребня - ridge regression), увеличение значения поможет уменьшить переобучение.
=========================
Min_child_weight: вы будете использовать этот параметр для управления переоснащением, поскольку он представляет собой минимальную сумму весов всех наблюдений, необходимых для дочернего элемента,
поэтому чем выше ценность моей помощи, чтобы предотвратить изучение моделью очень специфических отношений, но также это может привести к недообучению. Поэтому вы должны быть осторожны, используя его, и его настройка является неотъемлемой частью процесса настройки гиперпараметра xgboost.
==========================
subsample: обозначает долю наблюдений, которые будут случайным образом отобраны для каждого дерева, Более низкие значения делают алгоритм более консервативным и предотвращают переобучение, но слишком малые значения могут привести к недостаточному подбору.
Итак, теперь, когда вы понимаете, каковы наиболее важные параметры настройки гиперпараметров Xgboost (параметры бустера),
обратите внимание, что теперь вы не должны злоупотреблять ими, например, используя чрезвычайно высокие или низкие значения.
так как это приведет к переобучению или недообучению в зависимости от гиперпараметра, с которым вы имеете дело,
и теперь, когда у вас есть эта заметка, пришло время обсудить параметры обучения xgboost.
=========================
Параметры задачи обучения Xgboost
Эти параметры используются для определения цели оптимизации, а метрика рассчитывается на каждом этапе. Этот тип параметра включает в себя два основных параметра: цель и показатель проверки:
objective: он определяет функцию потерь, которая должна быть минимизирована, например, если это регрессия с использованием квадрата ошибки или квадрат логарифмических потерь как функция потерь или классификация, и если это классификация.
Является ли бинарным использование логистической регрессии или вероятностного вывода или использование потерь на петлях в качестве функции потерь, который возвращает бинарную классификацию, или мы говорим о случае мультиклассовой классификации в котором использовать softmax или softprob, вывод которых является вероятностью.
Eval_metric: этот параметр связан с используемым инструментом проверки, например: rmse, mae,logloss, error, merror, auc, aucpr.
==========================
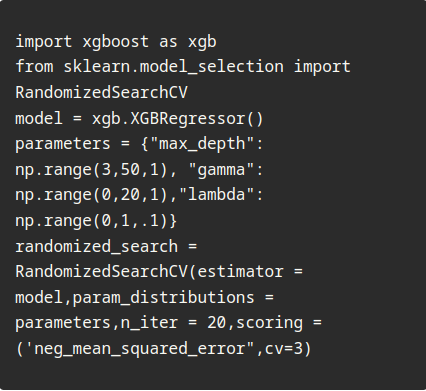
Гиперпараметр Xgboost настраивает приложение Python с использованием рандомизированного поиска cv
В первую очередь мы собираемся:
импортировать библиотеки и данные, которые мы будем обучать,
а затем мы будем выбирать, какие гиперпараметры xgboost будут настроены с помощью randomizedsearchcv путем определения диапазонов поиска значений каждого гиперпараметра как мы делали раньше в сетке поиска cv. Подгонка модели поиска к данным получение лучших гиперпараметров, обеспечивающих наилучшую производительность Да, это так просто, теперь давайте закодируем это:
Заключение
Алгоритм Xgboost — один из самых важных и продвинутых алгоритмов машинного обучения, когда-либо существовавших и это дает вам возможность высокой гибкости благодаря большому количеству гиперпараметров, кроме того, он может решать многие проблемы, такие как отсутствующие данные, и контролировать как переобучение, так и недообучение, это хорошо настраиваемый алгоритм, но для получения наилучших результатов требуется много усилий.
Смотри: Использование XGBoost in Python