Для чего нужен Dropout в машинном обучении?
ПрограммированиеМашинное обучение+2
Анонимный вопросМашинное обучение и Нейронные сети
· 6,0 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 22 мар 2022
Что такое Dropout в нейронных сетях?
Проще говоря, Dropout относится к игнорированию единиц (то есть нейронов) во время фазы обучения определенного набора нейронов, который выбирается случайным образом. Под «игнорированием» подразумевается, что эти юниты не учитываются во время конкретного прохода вперед или назад. С технической точки зрения, на каждом этапе обучения отдельные узлы либо исключаются из сети с вероятностью 1-p, либо сохраняются с вероятностью p, так что остается уменьшенная сеть; входящие и исходящие ребра к выпадающему узлу также удаляются.
===================
Зачем нам нужен Dropout?
Учитывая, что мы немного знаем о дропаутах, возникает вопрос — зачем нам вообще нужен дропаут? Почему нам нужно буквально отключать части нейронных сетей?
Ответ на эти вопросы — «для предотвращения чрезмерного переобучения ».
Полностью связанный слой занимает большую часть параметров, и, следовательно, нейроны развивают взаимную зависимость друг от друга во время обучения, что ограничивает индивидуальную мощность каждого нейрона, что приводит к переподгонке обучающих данных.
===================
Dropout - детально
===================
Теперь, когда мы немного знаем об отсеве и мотивации, давайте углубимся в детали. Если вам просто нужен обзор отсева в нейронных сетях, двух предыдущих разделов будет достаточно. В этом коснемся еще некоторых технических аспектов. В машинном обучении регуляризация — это способ предотвратить переобучение. Регуляризация уменьшает переобучение, добавляя штраф к функции потерь. Добавляя этот штраф, модель обучается так, что она не изучает взаимозависимый набор весов признаков. Те из вас, кто знаком с логистической регрессией, могут быть знакомы с штрафами L1 (лапласиан) и L2 (гауссов).
Dropout — это подход к регуляризации в нейронных сетях, который помогает уменьшить взаимозависимое обучение нейронов.
Фаза обучения:
Фаза обучения: для каждого скрытого слоя, для каждой обучающей выборки, для каждой итерации игнорируйте (обнуляйте) случайную долю p узлов (и соответствующих активаций).
Этап тестирования:
Используйте все активации, но уменьшите их на коэффициент "p" (чтобы учесть недостающие активации во время обучения).

Некоторые наблюдения:
Dropout заставляет нейронную сеть изучать более надежные функции, которые полезны в сочетании со многими различными случайными подмножествами других нейронов.Dropout примерно удваивает количество итераций, необходимых для сходимости. Однако время обучения для каждой эпохи меньше. Имея H скрытых единиц, каждую из которых можно сбросить, имеем. 2^H возможных моделей. На этапе тестирования рассматривается вся сеть, и каждая активация уменьшается в "p" раз.
=====================
Эксперимент в Керасе
=====================
Проверим эту теорию на практике. Чтобы увидеть, как работает отсев, построим глубокую сеть в Keras и попытаемся проверить ее на наборе данных CIFAR-10. Построенная глубокая сеть имеет три сверточных слоя размером 64, 128 и 256, за которыми следуют два плотно связанных слоя размером 512 и плотный слой выходного слоя размером 10 (количество классов в наборе данных CIFAR-10).
ReLU взята в качестве функции активации для скрытых слоев и сигмоид для выходного слоя (это стандарты, особо не экспериментировали с их изменением). Использована стандартная категориальная кросс-энтропийная потеря. Использован отсев во всех слоях и увеличив доля отсева с 0,0 (отсутствие отсева вообще) до 0,9 с размером шага 0,1 и прогнал каждый из них до 20 эпох. Результаты выглядят следующим образом:
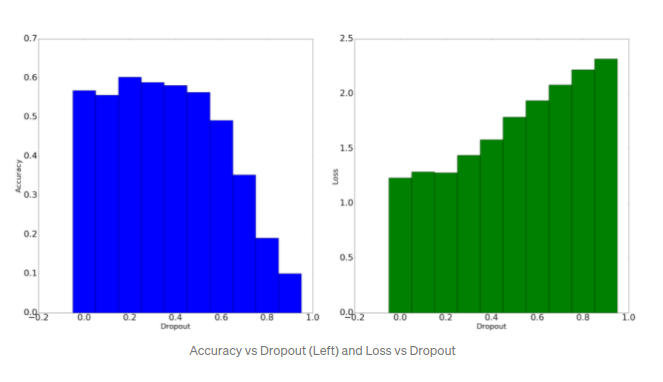
Из приведенных выше графиков мы можем сделать вывод, что с увеличением отсева происходит некоторое увеличение точности проверки и снижение убытка изначально, прежде чем тренд начнет идти вниз. Может быть две причины снижения тренда, если доля отсева равна 0,2: 0,2 — фактические минимумы для этого набора данных, сети и используемых параметров набора.
Для обучения сетей требуется больше эпох.