Для чего нужен train_test_split в sklearn?
ПрограммированиеМашинное обучение+3
Анонимный вопросМашинное обучение и Нейронные сети
· 4,0 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 14 апр 2022
Когда вы оцениваете прогностическую эффективность вашей модели, очень важно, чтобы процесс был беспристрастным. Используя train_test_split() из библиотеки обработки данных scikit-learn, вы можете разделить свой набор данных на подмножества, чтобы свести к минимуму возможность смещения в процессе оценки и проверки.
===================
Наборы для обучения, проверки и тестирования
===================
Разделение набора данных необходимо для беспристрастной оценки эффективности прогнозирования. В большинстве случаев достаточно случайным образом разделить набор данных на три подмножества:
Тренировочный набор применяется для обучения или подгонки вашей модели. Например, вы используете обучающий набор, чтобы найти оптимальные веса или коэффициенты для линейной регрессии, логистической регрессии или нейронных сетей.
Набор проверки используется для беспристрастной оценки модели во время настройки гиперпараметров. Например, когда вы хотите найти оптимальное количество нейронов в нейронной сети или лучшее ядро для метода опорных векторов, вы экспериментируете с разными значениями. Для каждой рассматриваемой настройки гиперпараметров вы подгоняете модель к обучающему набору и оцениваете ее производительность с помощью проверочного набора.
Набор тестов необходим для объективной оценки окончательной модели. Вы не должны использовать его для подгонки или проверки.
====================
Недообучение и переобучение
====================
Разделение набора данных также может быть важно для определения того, страдает ли ваша модель одной из двух очень распространенных проблем, называемых недообучением и переобучением:
Недостаточное обучение обычно является следствием того, что модель не может инкапсулировать отношения между данными. Например, это может произойти при попытке представить нелинейные отношения с помощью линейной модели. Недообученные модели, вероятно, будут иметь плохую производительность как с обучающими, так и с тестовыми наборами.
Переобучение обычно имеет место, когда модель имеет чрезмерно сложную структуру и изучает как существующие отношения между данными, так и шум. Такие модели часто имеют плохие возможности обобщения. Хотя они хорошо работают с обучающими данными, они обычно плохо работают с невидимыми (тестовыми) данными.
=======================
Вы можете использовать обучающий набор (x_train и y_train) для подбора модели и тестовый набор (x_test и y_test) для объективной оценки модели.
Вы можете применить три известных алгоритма регрессии для создания моделей, соответствующих вашим данным:
=======================
1.Linear regression with LinearRegression()
2.Gradient boosting with GradientBoostingRegressor()
3.Random forest with RandomForestRegressor()
======================
и далее импортируйте нужные вам классы.
Создайте экземпляры модели, используя эти классы.
Сопоставьте экземпляры модели с .fit(), используя обучающий набор.
Оцените модель с помощью .score(), используя набор тестов.
=======================
Учитывая две последовательности, такие как x и y здесь, train_test_split()
выполняет разделение и возвращает четыре последовательности в следующем порядке:
x_train: The training part of the first sequence (x)
x_test: The test part of the first sequence (x)
y_train: The training part of the second sequence (y)
y_test: The test part of the second sequence (y)
========================
Вот код, который следует описанным выше шагам для всех трех алгоритмов регрессии:
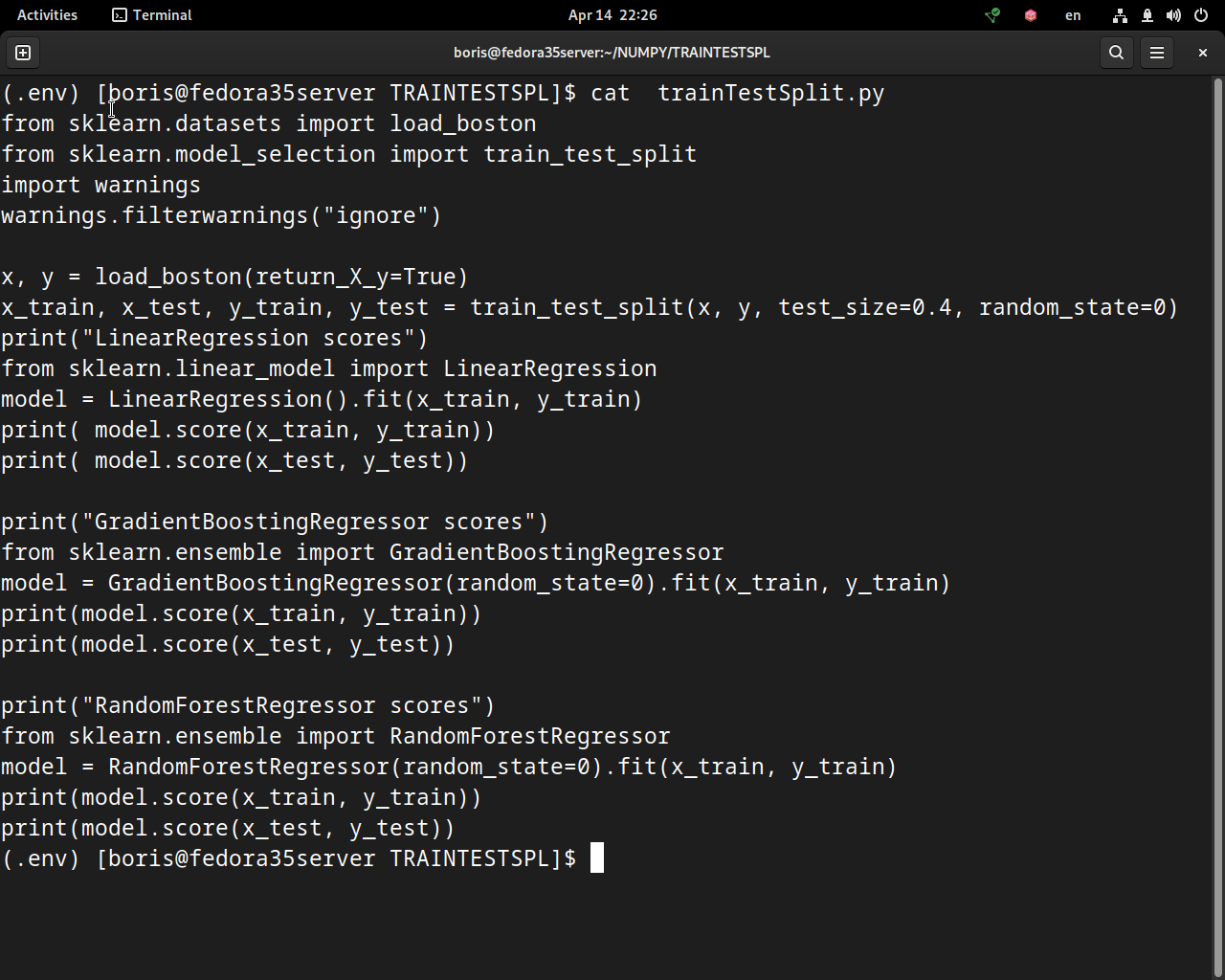
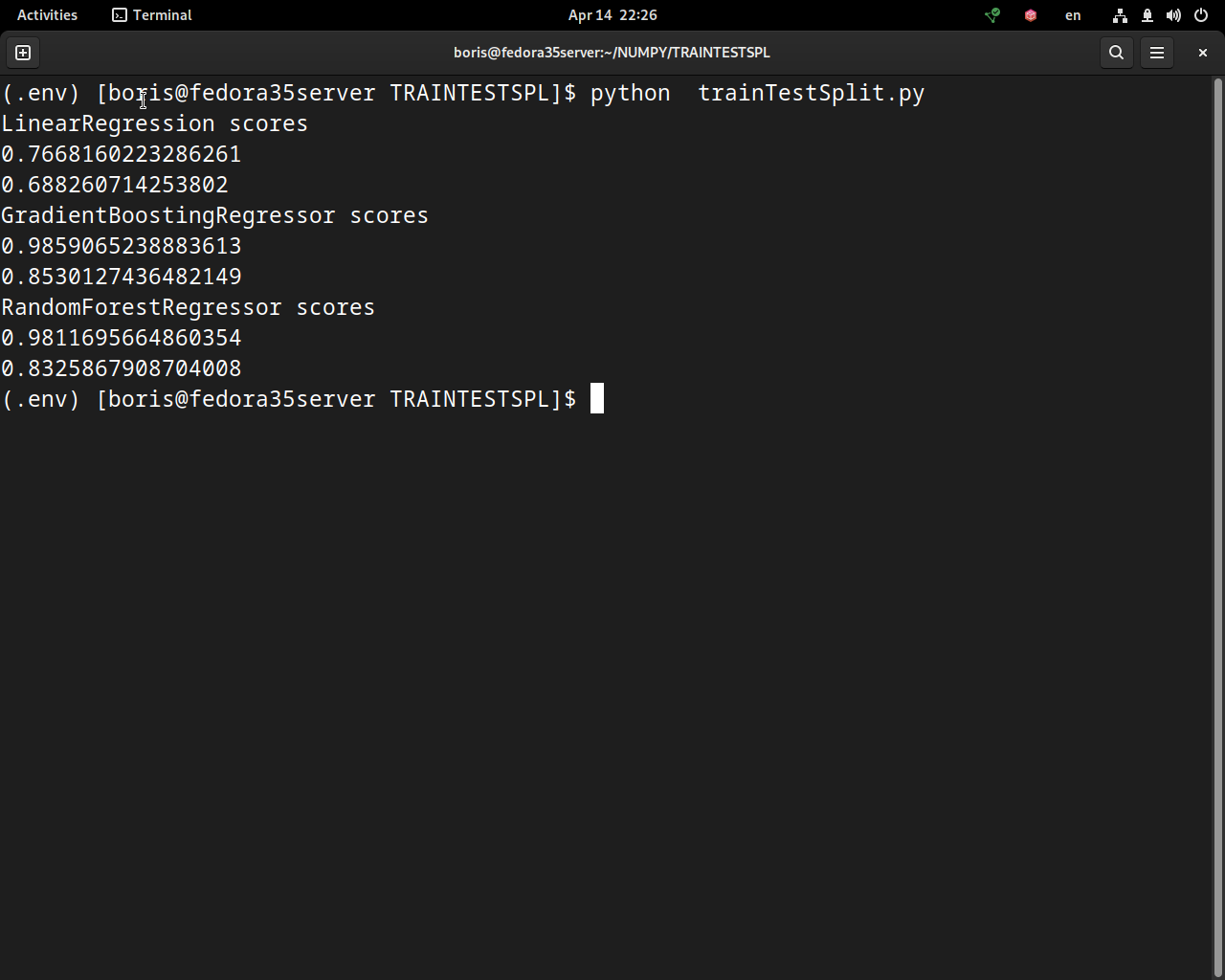
Вы использовали обучающие и тестовые наборы данных, чтобы подогнать три модели и оценить их производительность. Мерой точности, полученной с помощью .score(), является коэффициент детерминации. Его можно рассчитать с помощью обучающего или тестового набора. Однако, как вы уже узнали, оценка, полученная с помощью тестового набора, представляет собой непредвзятую оценку производительности.
Вы можете указать необязательные аргументы для функций LinearRegression(), GradientBoostingRegressor() и RandomForestRegressor(). GradientBoostingRegressor() и RandomForestRegressor() используют параметр random_state по той же причине, что и train_test_split(): чтобы справиться со случайностью в алгоритмах и обеспечить воспроизводимость.
=======================
Вы можете использовать train_test_split() для решения задач классификации так же, как и для регрессионного анализа. В машинном обучении проблемы классификации включают в себя обучение модели применению меток или классификации входных значений и сортировке набора данных по категориям.
1 эксперт согласен