Первый
Описание проекта для курса "MLOps и production подход к ML исследованиям" от ods.ai
Название проекта:
Предсказание качества воздуха (AQI - air quality index)
- Краткое описание проекта
Постановка задачи
Построить модель, предсказывающую индекс качества воздуха по данным загрязнителей со станций выбранного района (области).

Описание данных
Данные взяты с сайта http://discomap.eea.europa.eu/ , предоставляющего информацию о загрязнителях, как исторических, так и актуальных. Регулярно проводится обновление данных. Наличие загрязнителей варьируется в зависимости от страны и от года. Поэтому было принято решение взять загрязнители, которые официально входят в состав индекса качества воздуха.
Это озон, SO2, NO2, CO и PM10, PM2.5 (твердые частицы соответствующего диаметра).
Выбрана страна Испания, так как в ней давно фиксируются различное количество загрязнителей и присутствует множество станций. Также в качестве альтернативного эксперимента (и реализации использования тегов для git и dvc) выбрана Латвия в сугубо личных интересах участника команды.
Результаты анализа и обработки данных
Была проведена проверка данных, установлен регулярный временной шаг. Пропуски оставили пустыми, так как при расчете индекса одним из условий было, чтобы в окне содержалось определенное количество измерений. Произведена проверка на выбросы, и если таковые имелись, анализ на то, что это не ошибка измерения.
Как пример, высокое значение индекса (см рисунок ниже) - это итог резкого выброса мелких и крупных частиц. Значение было бы сильно выше, если бы мы не использовали среднее за день, а часовое значение. Но даже в таком случае, оно не считалось бы выбросом, так как это не ошибка измерения, а такое реальное значение.
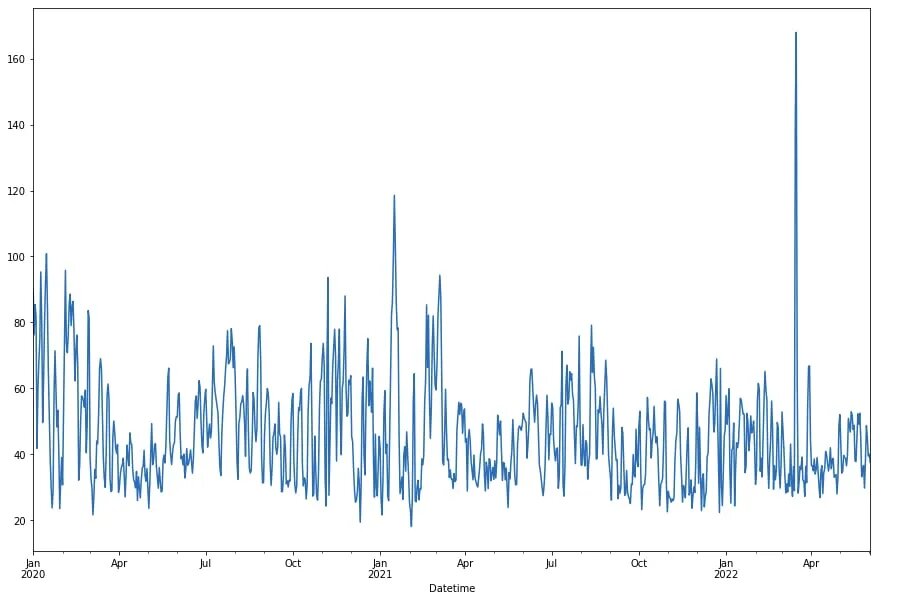
После расчетов всех индексов и самого AQI пустые значения были проинтерполированы.
При анализе временного ряда таргета выяснилось, что ряд стационарный, с автокорреляцией, в большей степени с авторегрессионным процессом и еженедельной повторяемостью (угадайте в какой день пиковое значение!).
Результаты feature engineering
Изначально планировалось посчитать только AQI на основе необходимых загрязнителей, и использовать его же в задаче предсказания временного ряда. Однако в ходе исследования было выяснено, что лучший результат получается, если оставить средние значения загрязнителей (рассчитанные по необходимом окну из статьи), а не расчет их индекса, так как предсказание AQI на основе предыдущих значений выдавало ошибку выше или совсем немного ниже, чем наивная модель (завтра будет так же как сегодня).
Используемые методы оптимизации
Поиск гипер парметров производился методом RandomSearch
Итоговая модель XGBoost
Метрики качества
Для контроля качества модели использовались метрики RMSE и MAE, типичные для временных рядов
- Описание MLOPS подходов
Система контроля версий - git (github), взят как бесплатный и знакомый веб-сервис.
Инструменты контроля codestyle - black, flake8. В силу отсутствия какого-либо опыта с линтерами и автоформаттерами, выбраны те, что упоминаются в лекциях, в целом пока не было претензий, их и оставили.
Шаблон проекта - основа cookiecutter datascience + вынесена мета информация (о выгрузке из источника, необходимые константы для расчета и тп)
Инструменты шаблонизации структуры проекта - cookiecutter datascience, очень понравилась структура проекта, и что вносить изменений пришлось совсем немного.
Workflow менеджеры - dvc, уже был положительный опыт с ним. Очень понятные стейджи, если прописывать в ямле. Видно зависимости каждого стейджа и результат. Удобно, что можно стейдж запускать по циклу. С dvc стало возможным хранение в облаке данных, которые довольно долго выгружаются на первом этапе, и теперь при переходе на другую машину можно не запускать выгрузку, а забрать уже выгруженные данные.
Инструменты трекинга экспериментов - MLflow, тут тоже нет опыта, оставили его, чтобы распробовать
Методы и инструменты тестирования - pytest. Так как проект исследовательский и времени покрывать тестами весь код нет, юнит-тесты практически отсутствуют, упор сделан на проверку данных, которые идут в расчеты и на обучение модели.
Описание CI пайплайна - CI/CD был реализован в github actions. Основная часть CI состоит из этапа стилистической проверки и этапа запуска тестов. В гитхабе это реализовано в формате джоб (job): одна джоба активирует виртуальное окружение, устанавливает black и flake8 и проверяет скрипты; вторая джоба устанавливает poetry, инсталлирует библиотеки, делает dvc pull данных из s3 и запускает тесты на проверку данных. Все джобы CI-части отрабатывают на Github-hosted раннерах (так как dvc pull там работает в разы быстрее).
- Описание получившегося сервиса/продукта
Технологический стек
- Операционные системы: Ubuntu 18.04, Windows 10, macOS Monterey
- Язык разработки: Python 3.9
- Менеджмент зависимостей и виртуальных сред: Poetry
- Система контроля версий: git (github)
- Система контроля версий данных: dvc, yandex s3
- Шаблонизатор: coockiecutter
- Линтер: flake8
- Автоформаттер: black
- CLI: click
- Трекинг экспериментов: MLflow
- ML-стэк: xgboost, sklearn, statsmodels, pandas, numpy
- Тестирование: pytest
- Докеризация: реализованы все контейнеры из лекции (minio, nginx, postgres, pgadmin, mlflow, model_service, nexus)
API
- FastAPI
Мониторинг
- MLflow
Описание CD пайплайна
CD часть включает в себя часть с отправкой докерфайла в Github registry. Сохранялись все секретки в гитхабе, по которым логинился раннер и пушил указанный имедж. Эта часть работала с Github-hosted раннером.
Этап деплоя реализовывался на self-hosted раннере. Также, как в лекциях, билдился контейнер (с удалением старого) из ранее отправленного имеджа.
- Проблемы и недостатки текущего workflow и получившихся результатов. Возможные улучшения.
Проблемы:
- dvc pull в шаге тестов выгружает исторические данные, которые весят много и не нужны (хорошо бы выгружать частично для тестов)
- обновленные данные пока что выгружаются в ручную
- Часть кода не покрыта тестами
- В идеале, так как загрязнители сильно связаны с днями неделями, найти источники данных трафика и добавить в фичи.
Решения:
- Для апдейта можно подключить airflow, сохранять отдельно и при обучении включать в исторические данные, чтобы не выгружать последние заново долго.
- Добавить тесты.
5. Описание ролей в команде
Никитина Ксения - автор и разработчик проекта
Артур Яничев - участливый наблюдатель