Решение учебной задачи "House Prices - Advanced Regression Techniques" для курса "MLOps и production подход к ML исследованиям"
ОПИСАНИЕ ML ПРОЕКТА
Постановка задачи
Данная статья является описанием финального проекта по пройденному мной курсу "MLOps и production подход к ML исследованиям". Было бы неплохо применить полученные знания на каком-нибудь интересном пет проекте, связанном с ML, но времени как всегда не хватало, поэтому полученные знания применял на пройденной учебной задаче в Kaggle "House Prices - Advanced Regression Techniques". Репозиторий проекта в gitlab.
Описание данных
Суть задачи является в прогнозировании цен на недвижимость. В качестве метрики оценки прогноза была Root-Mean-Squared-Error (RMSE). Для прогнозирования было предоставлено 79 независимыми переменными, описывающими (почти) каждый аспект жилых домов в Эймсе, штат Айова. Стоит отметить, что особенностью данных является большое количество категориальных признаков.
Анализ данных
Если объединить тренировочный и тестовый датафреймы и вызвать для результата функцию info, то увидим такую общую иформацию о данных:
RangeIndex: 2919 entries, 0 to 2918
Data columns (total 81 columns):
dtypes: float64(12), int64(26), object(43)
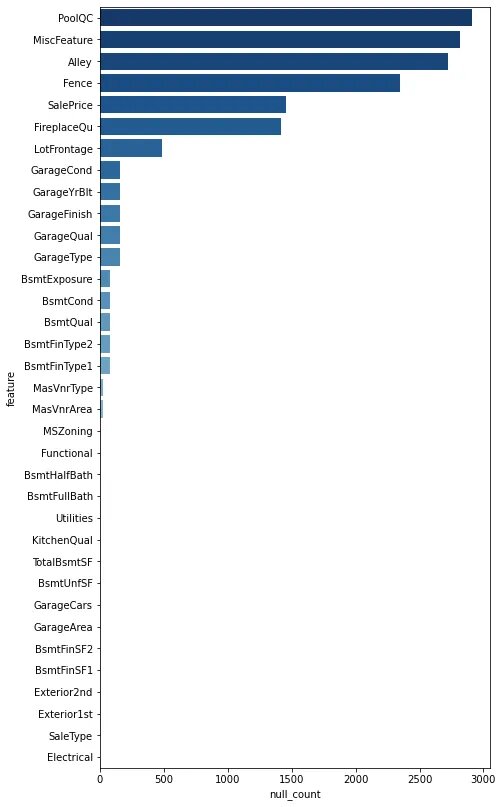
Подробный список по полям занимает слишком много места, поэтому ниже привел график полей с пропусками.
RangeIndex: 2919 entries, 0 to 2918
Data columns (total 81 columns):
dtypes: float64(12), int64(26), object(43)
Подробный список по полям занимает слишком много места, поэтому ниже привел график полей с пропусками.
Ниже представлена гистограмма цен в train

Перед обучением модели логарифмируем цены, чтобы нормализовать распределение, а так же данное действие поможет в вычислении метрики, т.к. предсказывая цену напрямую при вычислении метрики в логарифме может оказаться отрицательное значение.

Подготовка данных
Стоит отметить, что есть категориальные фичи, в которых пропуски имеют смысловую нагрузку исходя из справочника значений, предоставленного в задаче. Например, для фичи PoolQC (Pool quality) пропуск интерпретируется как "No Pool". В таких случаях больше всего пропусков и они заполнялись отдельным значением "None". В остальных случаях пропуски не несли в себе смысловой нагрузки и были заполнены модой. Числовые фичи были заполнены медианой.
Пере обучением были сделаны следующие преобразования с данными:
- Числовые фичи были отмасштабированы через StandartScaler
- Категориальные признаки были переведены в разряженный вид с помощью Hashing Trick
Обучение моделей
В качестве моделей были выбраны:
- KernelRidge
- XGBRegressor
- Стекинг алгоритмов
Гиперпараметры моделей подбирались с помощью GridSearchCV
ОПИСАНИЕ MLOPS ПОДХОДОВ И ИНСТРУМЕНТОВ
Системой контроля версий для проекта был выбран Git на платформе GitLab. Работал когда-то с GitLab на уровне обычных пушей репозиторий, но часть с настройкой пайплайна CI было для меня новым и достаточно познавательным опытом. Для работы CI в репозитории был создан CI/CD runner, который был развернут локально.
Для приведения кода в порядок весь код проекта прошел через автоформатер Black. На уровне CI использовались линтеры:
Настройки flake описаны в файле .flake8.
Настройки mypy описаны в файле .mypy.ini
Чтобы не ломать голову над структурой проекта был использован шаблонизатор Cookiecutter, в котором уже есть шаблон DS проекта.
Выполнив одну команду из инструкции в корне проекта развернется структура папок, где есть почти все необходимое для DS проекта.
Выполнив одну команду из инструкции в корне проекта развернется структура папок, где есть почти все необходимое для DS проекта.
В качестве менеджера зависимостей в проекте был выбран Poetry, как наиболее современный и удобный инструмент.
В рамках курса рассматривалось два workflow менеджера snakemake и DVC. Для использования был выбран DVC, как более функциональный инструмент c версионированием данных и по моему мнению более интуитивно понятным оформлением плана запуска. Собственно сам план запуска проекта можно посмотреть в файле dvc.yaml. Для вызова функций в плане они было оформлены через модуль Click для вызова через CLI.
Для отдельного хранения данных проекта локально было развернуто MinIO S3 хранилище, куда они заливались с помощью DVC, а в gitlab шли только файлы метаданных.
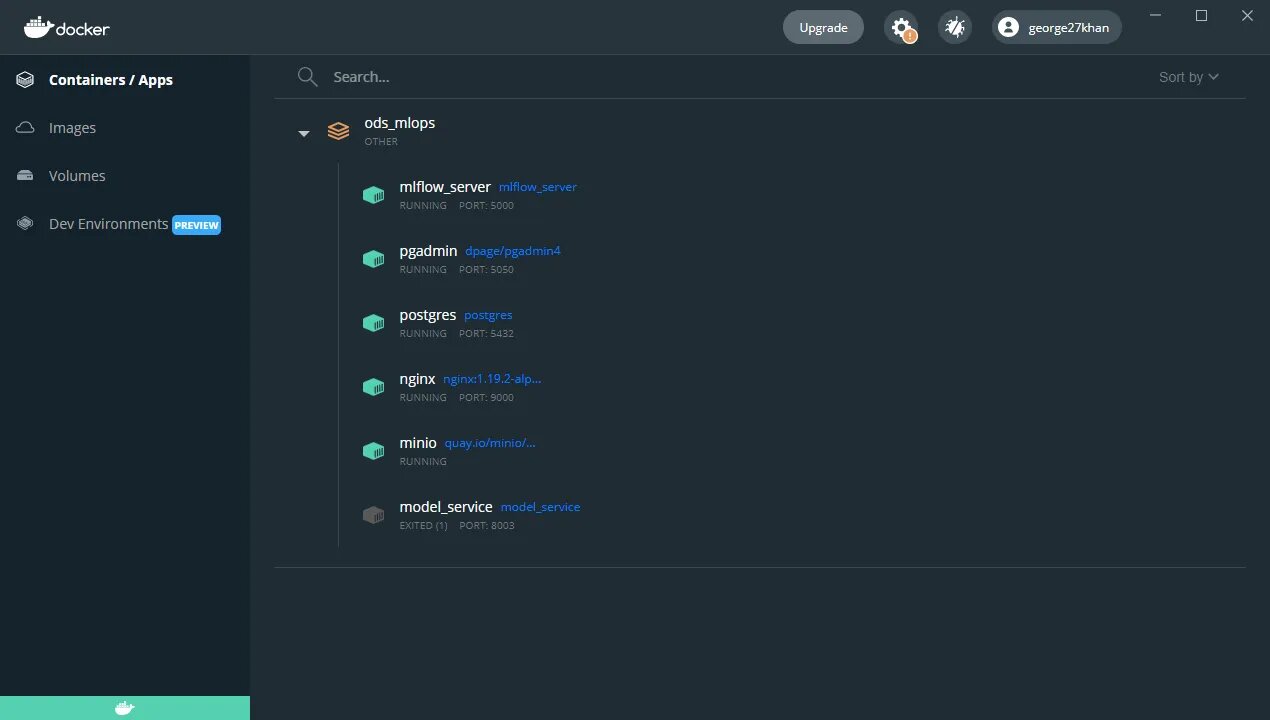
В курсе подробно рассматривалась система трекинга экспериментов MLflow, она и была взята для проекта. MLflow был развернут по 4 схеме из официальной документации, основой которой является удаленные трекинг сервер, хранилище данных и хранилище артефактов. В виду ограничения ресурсов все эти условия были реализованы локально через Docker контейнер.
Код проекта был базово покрыть автотестами с помощью модуля pytest, в дополнение к нему был использован модуль great_expectations для проверки данных в DataFrame.
В файле .gitlab-ci.yml можно ознакомится с пайплайном CI. В нем происходит кэширование данных, проверка версии python, тест кода, lint и type проверки.
ОПИСАНИЕ СЕРВИСА
Технологический стек
- Язык разработки: Python 3.9.0
- Менеджер зависимостей: poetry
- Система контроля версий: git (gitlab)
- Workflow менеджмент: DVC
- Хранилище для версионирования данных: Minio
- Шаблонизатор: Сoockiecutter
- Линтер: flake8, mypy
- Автоформаттер: black
- CLI: click
- Мониторинг: MLflow, postgres, minio, nginx, docker
ПРОБЛЕМЫ И НЕДОСТАТКИ ТЕКУЩЕГО WORKFLOW И ПОЛУЧИВШИХСЯ РЕЗУЛЬТАТОВ.
К сожалению, все манипуляции по workflow были по факту повторение решений автора курса.
В качестве проекта был взят достаточно простой пример.
Не получилось собрать в проект в докер образ и через restapi. Возникли проблемы в процессе сборки, которые небыли решены до крайнего срока написания статьи. Так же из-за отсутствие сборок модели не приступал к части с nexus.
Получилось немного скомканное решение, но в дальнейшем доделаю до конца реализацию по плану.