Как вывести формулу градиентного шага в методе логистической регрессии для задачи классификации с двумя классами?
ПрограммированиеМатематика+3
Анонимный вопросМашинное обучение и Нейронные сети
· 634
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 11 июл 2022
Мы используем логистическую регрессию для решения задач классификации, где результатом является дискретная переменная. Обычно мы используем его для решения задач бинарной классификации. Как следует из названия, задачи бинарной классификации имеют два возможных выхода.Определим модель логистической регрессии для задач бинарной классификации. Мы выбираем функцию гипотезы как сигмовидную функцию.

При решении задачи бинарной классификации логарифмическая стоимость ошибки зависит от значения y. Мы можем определить стоимость для двух случаев отдельно:

Поскольку вывод может быть либо {0}, либо {1}, мы можем упростить уравнение:

Градиентный спуск — это итеративный алгоритм оптимизации, который находит минимум дифференцируемой функции. В этом процессе мы пробуем разные значения и обновляем их, чтобы достичь оптимальных, сводя к минимуму результат. Применим этот метод к функции стоимости логистической регрессии. Таким образом, можно найти оптимальное решение, минимизирующее стоимость по параметрам модели:

где

Здесь «i» есть номер фактического класса . Подробно изложено в https://yandex.ru/q/business/12017084161/?answer_id=695dcec1-bbe0-4fd3-a59b-298dc583b154
Предположим, у нас есть всего n функций. В этом случае у нас есть n параметров для вектора theta. Чтобы минимизировать нашу функцию стоимости, нам нужно запустить градиентный спуск для каждого параметра theta_j:
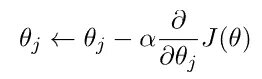
Чтобы завершить алгоритм, нам нужно значение частной производной по theta_j для J(theta), которое равно:

Включение этого в функцию градиентного спуска приводит к правилу обновления:

Неожиданно правило обновления такое же, как и правило, полученное с использованием суммы квадратов ошибок в линейной регрессии. В результате мы можем использовать ту же формулу градиентного спуска и для логистической регрессии. Перебирая обучающие выборки до сходимости, мы достигаем оптимальных параметров тета, ведущих к минимальным затратам.