Какие бывают алгоритмы кластеризации?
ПрограммированиеМашинное обучение+3
Алена КаменецкихМашинное обучение и Нейронные сети
· 1,3 K
Борис Державец3,1 K
Data science
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 16 дек 2021
Алгоритмы кластеризации
Есть много типов алгоритмов кластеризации.
Многие алгоритмы используют меры сходства или расстояния между примерами в пространстве признаков, чтобы обнаружить плотные области наблюдений. Таким образом, часто рекомендуется масштабировать данные до использования алгоритмов кластеризации.
Центральным для всех целей кластерного анализа является понятие степени сходства (или несходства) между отдельными объектами, объединяемыми в кластеры. Метод кластеризации пытается сгруппировать объекты на основе предоставленного ему определения сходства.
Некоторые алгоритмы кластеризации требуют, чтобы вы указали или угадали количество кластеров, которые необходимо обнаружить в данных, тогда как другие требуют указания некоторого минимального расстояния между наблюдениями, в котором примеры могут считаться «близкими» или «связанными».
Таким образом, кластерный анализ представляет собой итеративный процесс, в котором субъективная оценка идентифицированных кластеров учитывается при изменении конфигурации алгоритма до тех пор, пока не будет достигнут желаемый или подходящий результат.
Библиотека scikit-learn предоставляет на выбор набор различных алгоритмов кластеризации.
Список из 10 наиболее популярных алгоритмов выглядит следующим образом:
Распространение сродства
Агломеративная кластеризация
BIRCH
DBSCAN
К-средние
Мини-пакетные K-средние
Средний сдвиг
OPTICS
Спектральная кластеризация
Смесь гауссианов
===================
Каждый алгоритм предлагает свой подход к задаче обнаружения естественных групп в данных. Не существует лучшего алгоритма кластеризации и простого способа найти лучший алгоритм для ваших данных без использования контролируемых экспериментов.
В этом руководстве мы рассмотрим, как использовать каждый из этих 10 популярных алгоритмов кластеризации из библиотеки scikit-learn.
Примеры предоставят вам основу для копирования и вставки примеров и тестирования методов на ваших собственных данных.
===================
Набор данных кластеризации
Мы будем использовать функцию make_classification () для создания тестового набора данных двоичной классификации.
В наборе данных будет 1000 примеров с двумя входными функциями и одним кластером для каждого класса. Кластеры визуально очевидны в двух измерениях, так что мы можем построить данные с точечной диаграммой и раскрасить точки на графике по назначенному кластеру. Это поможет увидеть, по крайней мере, на тестовой задаче, насколько «хорошо» были идентифицированы кластеры.
Кластеры в этой тестовой задаче основаны на многомерном гауссиане, и не все алгоритмы кластеризации будут эффективны при идентификации этих типов кластеров. Таким образом, результаты этого руководства не должны использоваться в качестве основы для сравнения методов в целом.
Пример создания и обобщения синтетического набора данных кластеризации приведен ниже.

При выполнении примера создается синтетический набор данных кластеризации, а затем создается диаграмма рассеяния входных данных с точками, окрашенными меткой класса (идеализированные кластеры). Мы можем ясно видеть две отдельные группы данных в двух измерениях, и есть надежда, что алгоритм автоматической кластеризации сможет обнаружить эти группировки.
=========================
Распространение сродства
Распространение сродства включает в себя поиск набора примеров, которые наилучшим образом обобщают данные.
Мы разработали метод, называемый «распространение сродства», который принимает в качестве входных данных меры сходства между парами точек данных. Между точками данных происходит обмен сообщениями с действительным значением до тех пор, пока постепенно не появится высококачественный набор образцов и соответствующих кластеров.
- Кластеризация путем передачи сообщений между точками данных, 2007. Техника описана в статье:
Кластеризация путем передачи сообщений между точками данных, 2007.
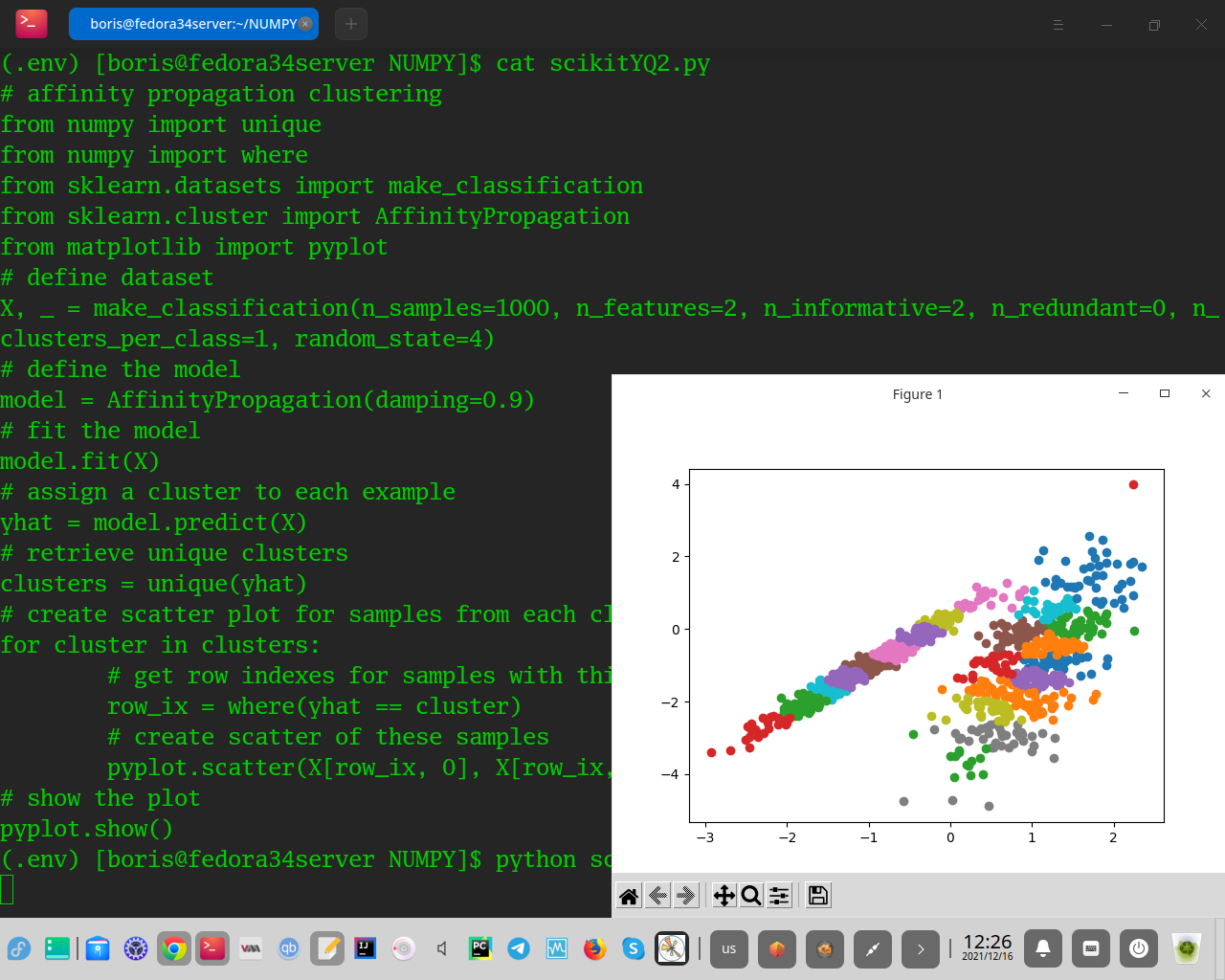
Это реализуется через класс AffinityPropagation, и основная конфигурация для настройки - это «демпфирование», установленное между 0,5 и 1 и, возможно, «предпочтение».
Выполнение примера соответствует модели в наборе обучающих данных и предсказывает кластер для каждого примера в наборе данных. Затем создается диаграмма рассеяния с точками, окрашенными в соответствии с назначенным им кластером. В этом случае мне не удалось добиться хорошего результата.
==================
Агломеративная кластеризация
Агломеративная кластеризация включает в себя слияние примеров до тех пор, пока не будет достигнуто желаемое количество кластеров.
Это часть более широкого класса методов иерархической кластеризации, и вы можете узнать больше здесь: Иерархическая кластеризация, Википедия. Он реализуется через класс AgglomerativeClustering, и основная конфигурация для настройки - это набор «n_clusters», оценка количества кластеров в данных. Полный пример приведен ниже.

Выполнение примера соответствует модели в наборе обучающих данных и предсказывает кластер для каждого примера в наборе данных. Затем создается диаграмма рассеяния с точками, окрашенными в соответствии с назначенным им кластером.
В этом случае разумная группировка найдена.
==================
Кластеризация BIRCH (BIRCH - сокращение от Balanced Iterative Reduction и Clustering using
Иерархии) включает построение древовидной структуры, из которой извлекаются центроиды кластера.
BIRCH постепенно и динамически кластеризует входящие многомерные метрические точки данных, чтобы попытаться произвести кластеризацию наилучшего качества с доступными ресурсами (то есть доступной памятью и временными ограничениями).
БЕРЧ: Эффективный метод кластеризации данных для больших баз данных, 1996.
Он реализуется через класс Birch, и основная конфигурация для настройки - это гиперпараметры «threshold» и «n_clusters», последний из которых обеспечивает оценку количества кластеров.
Полный пример приведен ниже.

Выполнение примера соответствует модели в наборе обучающих данных и предсказывает кластер для каждого примера в наборе данных. Затем создается диаграмма рассеяния с точками, окрашенными в соответствии с назначенным им кластером.
В этом случае обнаруживается отличная группировка.
===================
DBSCAN
Кластеризация DBSCAN (где DBSCAN - сокращение от Density-Based Spatial Clustering of Applications with Noise) включает в себя поиск областей с высокой плотностью в домене и расширение этих областей пространства функций вокруг них в виде кластеров.
… Мы представляем новый алгоритм кластеризации DBSCAN, основанный на концепции кластеров на основе плотности, который предназначен для обнаружения кластеров произвольной формы. DBSCAN требует только один входной параметр и помогает
Техника описана в статье:
Алгоритм на основе плотности для обнаружения кластеров в больших пространственных базах данных с шумом, 1996.
Он реализуется через класс DBSCAN, и основная конфигурация для настройки - это гиперпараметры «eps» и «min_samples».
Полный пример приведен ниже.
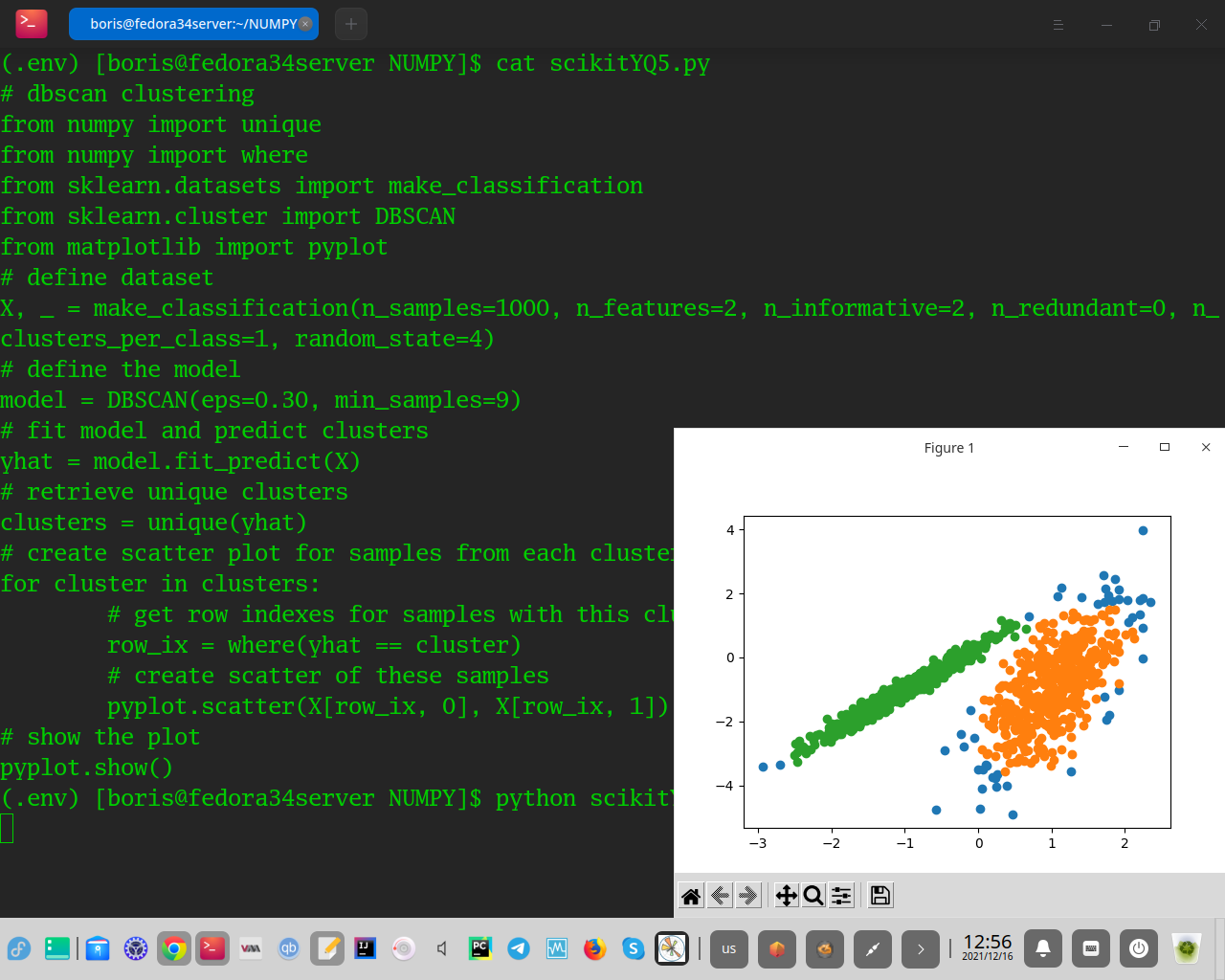
Выполнение примера соответствует модели в наборе обучающих данных и предсказывает кластер для каждого примера в наборе данных. Затем создается диаграмма рассеяния с точками, окрашенными в соответствии с назначенным им кластером.В этом случае разумная группировка найдена, хотя требуется дополнительная настройка.
====================
Модель гауссовой смеси
Модель гауссовой смеси суммирует многомерную функцию плотности вероятности со смесью гауссовских распределений вероятностей, как следует из ее названия. Он реализуется через класс GaussianMixture, и основная конфигурация для настройки - это гиперпараметр «n_clusters», используемый для указания предполагаемого количества кластеров в данных. Полный пример приведен ниже.
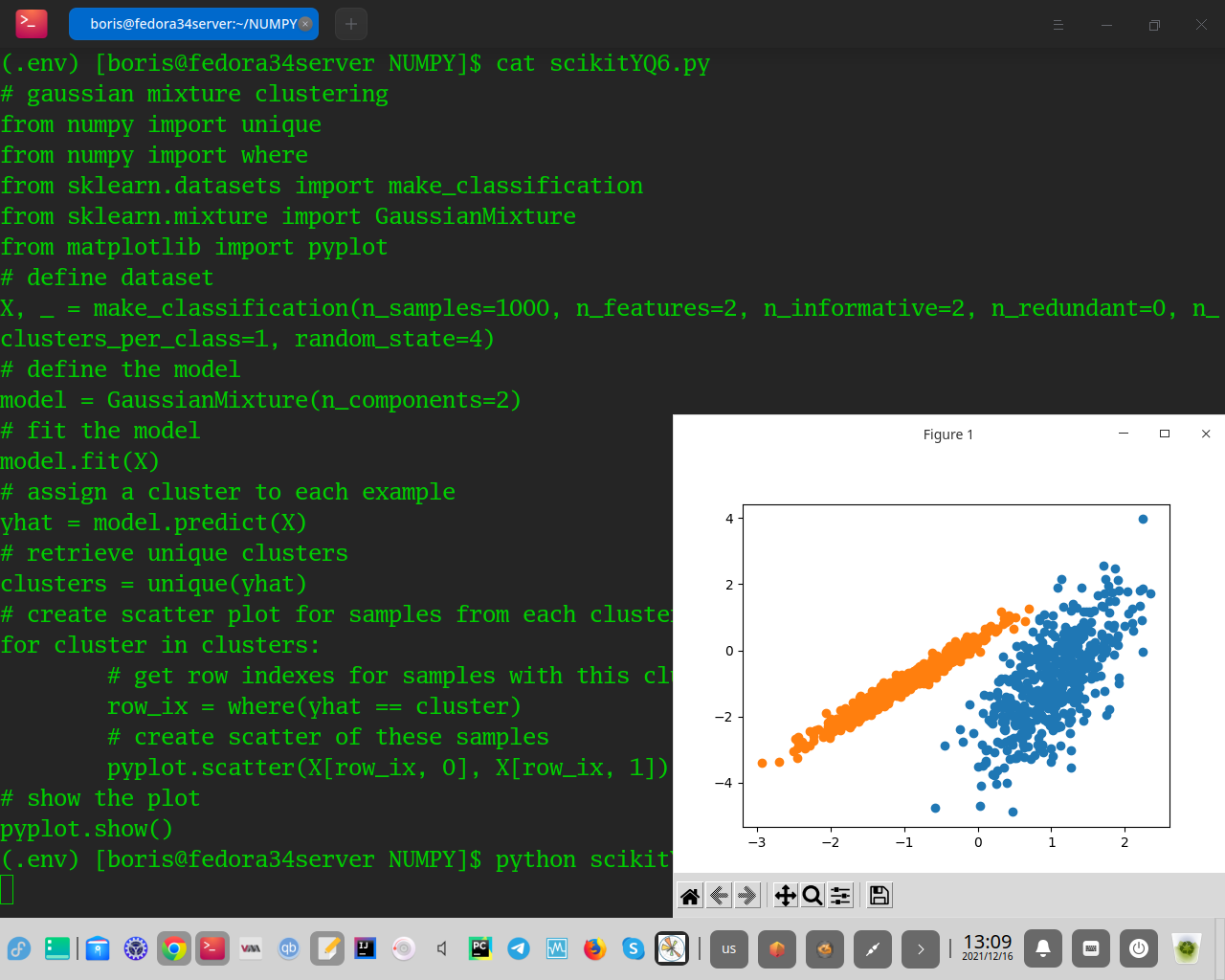
Выполнение примера соответствует модели в наборе обучающих данных и предсказывает кластер для каждого примера в наборе данных. Затем создается диаграмма рассеяния с точками, окрашенными в соответствии с назначенным им кластером. В этом случае мы видим, что кластеры идентифицированы идеально. Это неудивительно, учитывая, что набор данных был создан как смесь гауссианцев.
=====================
К-средние
Кластеризация K-средних может быть наиболее широко известным алгоритмом кластеризации и включает в себя присвоение примеров кластерам с целью минимизировать дисперсию внутри каждого кластера. Алгоритм реализуется через класс KMeans, и основная конфигурация для настройки - это гиперпараметр «n_clusters», установленный на оценочное количество кластеров в данных.
Полный пример приведен ниже.

Выполнение примера соответствует модели в наборе обучающих данных и предсказывает кластер для каждого примера в наборе данных. Затем создается диаграмма рассеяния с точками, окрашенными в соответствии с назначенным им кластером.
В этом случае обнаруживается разумная группировка, хотя неравномерная равная дисперсия в каждом измерении делает метод менее подходящим для этого набора данных.
Смотри далее по источнику https://machinelearningmastery.com/clustering-algorithms-with-python/
1,1 K
Комментировать ответ…Комментировать…