Каков физический смысл auc в машинном обучении и статистике?
ПрограммированиеМашинное обучение+3
Анонимный вопросМашинное обучение и Нейронные сети
· 3,0 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 29 янв 2022
Адресована только первая часть вопроса. Сокращения
AUC = площадь под кривой.
AUROC = площадь под кривой рабочих характеристик приемника.
AUC используется большую часть времени для обозначения AUROC, что является плохой практикой, поскольку, как указал Марк Класен, AUC неоднозначен (может быть любой кривой), а AUROC - нет.
==================
Интерпретация AUROC
AUROC имеет несколько эквивалентных интерпретаций:
1.Ожидание того, что равномерно выпавший случайный положительный результат ранжируется перед равномерно выпавшим случайным отрицательным.
2.Ожидаемая доля положительных результатов ранжируется перед равномерно нарисованным случайным отрицательным результатом.
3.Ожидаемый истинно положительный показатель, если ранжирование разделяется непосредственно перед равномерно нарисованным случайным отрицательным значением.
4.Ожидаемая доля отрицательных результатов ранжируется после равномерно нарисованного случайного положительного результата.
- Ожидаемый уровень ложных срабатываний, если ранжирование разделяется сразу после равномерного случайного срабатывания.
=================
Вычисление AUROC
Предположим, у нас есть вероятностный бинарный классификатор, такой как логистическая регрессия. Прежде чем представить кривую ROC (= кривую рабочих характеристик приемника), необходимо понять концепцию матрицы путаницы.
Когда мы делаем бинарный прогноз, может быть 4 типа результатов:
Мы предсказываем 0, в то время как истинный класс на самом деле равен 0: это называется True Negative, т.е. мы правильно предсказываем, что класс отрицательный (0). Например, антивирус не определил безобидный файл как вирус.
Мы предсказываем 0, в то время как истинный класс на самом деле равен 1: это называется ложным отрицанием, т. е. мы неправильно предсказываем, что класс отрицательный (0). Например, антивирус не смог обнаружить вирус.
Мы предсказываем 1, в то время как истинный класс на самом деле равен 0: это называется ложным срабатыванием, т. е. мы неправильно предсказываем, что класс положительный (1). Например, антивирус считал безобидный файл вирусом.
Мы предсказываем 1, в то время как истинный класс на самом деле равен 1: это называется True Positive, т.е. мы правильно предсказываем, что класс положительный (1). Например, антивирус правильно обнаружил вирус.
================
Чтобы получить матрицу путаницы, мы просматриваем все прогнозы, сделанные моделью, и подсчитываем, сколько раз происходит каждый из этих 4 типов результатов:

В этом примере матрицы путаницы среди 50 классифицированных точек данных 45 классифицированы правильно, а 5 классифицированы неправильно.
Поскольку для сравнения двух разных моделей часто удобнее иметь одну метрику, а не несколько, мы вычисляем две метрики из матрицы путаницы, которые позже объединим в одну:
=========================
Истинный положительный показатель (TPR), он же. чувствительность, частота попаданий и отзыв, который определяется как TP/(TP+FN). Интуитивно эта метрика соответствует доле положительных точек данных, которые правильно считаются положительными по отношению ко всем положительным точкам данных. Другими словами, чем выше TPR, тем меньше положительных точек данных мы пропустим.
==========================
Ложноположительный показатель (FPR), он же. выпадение, которое определяется как FP/(FP+TN). Интуитивно эта метрика соответствует доле отрицательных точек данных, которые ошибочно считаются положительными, по отношению ко всем отрицательным точкам данных. Другими словами, чем выше FPR, тем больше отрицательных точек данных будет классифицировано неправильно.
=========================
Чтобы объединить FPR и TPR в одну метрику, мы сначала вычисляем две предыдущие метрики с разными пороговыми значениями (например, 0,00; 0,01, 0,02,…, 1,00) для логистической регрессии, а затем наносим их на один график с значения FPR по оси абсцисс и значения TPR по оси ординат. Полученная кривая называется кривой ROC, а метрика, которую мы рассматриваем, — это AUC этой кривой, которую мы называем AUROC.

Пример метрики рабочей характеристики приемника (ROC) для оценки качества выходных данных классификатора.
Кривые ROC обычно показывают истинное положительное значение по оси Y и ложноположительное значение по оси X. Это означает, что верхний левый угол графика является «идеальной» точкой — ложноположительный показатель равен нулю, а истинно положительный показатель равен единице. Это не очень реалистично, но это означает, что большая площадь под кривой (AUC) обычно лучше. «Крутизна» ROC-кривых также важна, поскольку она идеальна для максимизации истинно положительного уровня при минимизации ложноположительного уровня. Кривые ROC обычно используются в двоичной классификации для изучения выходных данных классификатора. Чтобы расширить кривую ROC и область ROC до классификации с несколькими метками, необходимо бинаризировать выходные данные. Для каждой метки можно построить одну ROC-кривую, но можно также построить ROC-кривую, рассматривая каждый элемент матрицы индикатора метки как бинарное предсказание (микроусреднение). Другой мерой оценки для классификации с несколькими метками является макроусреднение, придающее равный вес классификации каждой метки.
"""
=======================================
Receiver Operating Characteristic (ROC)
=======================================
Пример метрики рабочих характеристик приемника (ROC) для оценки
качество вывода классификатора.
Кривые ROC обычно имеют истинную положительную скорость по оси Y и ложную
положительная скорость по оси X. Это означает, что верхний левый угол графика
"идеальная" точка - ложноположительный показатель нуля и истинно положительный показатель
один. Это не очень реалистично, но это означает, что большая площадь под
кривая (AUC) обычно лучше.
«Крутизна» ROC-кривых также важна, так как она идеальна для максимизации
истинная положительная скорость при минимизации ложноположительной скорости.
Кривые ROC обычно используются в двоичной классификации для изучения выходных данных
классификатор. Чтобы расширить кривую ROC и область ROC до нескольких меток
классификации необходимо бинаризировать вывод. Один ОКР
кривую можно нарисовать для каждой метки, но можно также нарисовать кривую ROC, учитывая
каждый элемент матрицы индикатора метки как бинарное предсказание
(микроусреднение).
Еще одна оценочная мера для классификации с несколькими метками
макроусреднение, придающее равный вес классификации каждого
метка.Еще одна оценочная мера для классификации с несколькими метками
макроусреднение, придающее равный вес классификации каждого метка.
.. note::
See also :func:`sklearn.metrics.roc_auc_score`,
:ref:`sphx_glr_auto_examples_model_selection_plot_roc_crossval.py`
"""
import numpy as np
import matplotlib.pyplot as plt
from itertools import cycle
from sklearn import svm, datasets
from sklearn.metrics import roc_curve, auc
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import label_binarize
from sklearn.multiclass import OneVsRestClassifier
from sklearn.metrics import roc_auc_score
# Import some data to play with
iris = datasets.load_iris()
X = [iris.data](http://iris.data)
y = [iris.target](http://iris.target)
# Binarize the output
y = label_binarize(y, classes=[0, 1, 2])
n_classes = y.shape[1]
# Add noisy features to make the problem harder
random_state = np.random.RandomState(0)
n_samples, n_features = X.shape
X = np.c_[X, random_state.randn(n_samples, 200 * n_features)]
# shuffle and split training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
# Learn to predict each class against the other
classifier = OneVsRestClassifier(
svm.SVC(kernel="linear", probability=True, random_state=random_state)
)
y_score = [classifier.fit](http://classifier.fit)(X_train, y_train).decision_function(X_test)
# Compute ROC curve and ROC area for each class
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(n_classes):
fpr[i], tpr[i], _ = roc_curve(y_test[:, i], y_score[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
# Compute micro-average ROC curve and ROC area
fpr["micro"], tpr["micro"], _ = roc_curve(y_test.ravel(), y_score.ravel())
roc_auc["micro"] = auc(fpr["micro"], tpr["micro"])
# %%
# Plot of a ROC curve for a specific class
plt.figure()
lw = 2
plt.plot(
fpr[2],
tpr[2],
color="darkorange",
lw=lw,
label="ROC curve (area = %0.2f)" % roc_auc[2],
)
plt.plot([0, 1], [0, 1], color="navy", lw=lw, linestyle="--")
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Receiver operating characteristic example")
plt.legend(loc="lower right")
[plt.show](http://plt.show)()
# %%
# Plot ROC curves for the multiclass problem
# ..........................................
# Compute macro-average ROC curve and ROC area
# First aggregate all false positive rates
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(n_classes)]))
# Then interpolate all ROC curves at this points
mean_tpr = np.zeros_like(all_fpr)
for i in range(n_classes):
mean_tpr += np.interp(all_fpr, fpr[i], tpr[i])
# Finally average it and compute AUC
mean_tpr /= n_classes
fpr["macro"] = all_fpr
tpr["macro"] = mean_tpr
roc_auc["macro"] = auc(fpr["macro"], tpr["macro"])
# Plot all ROC curves
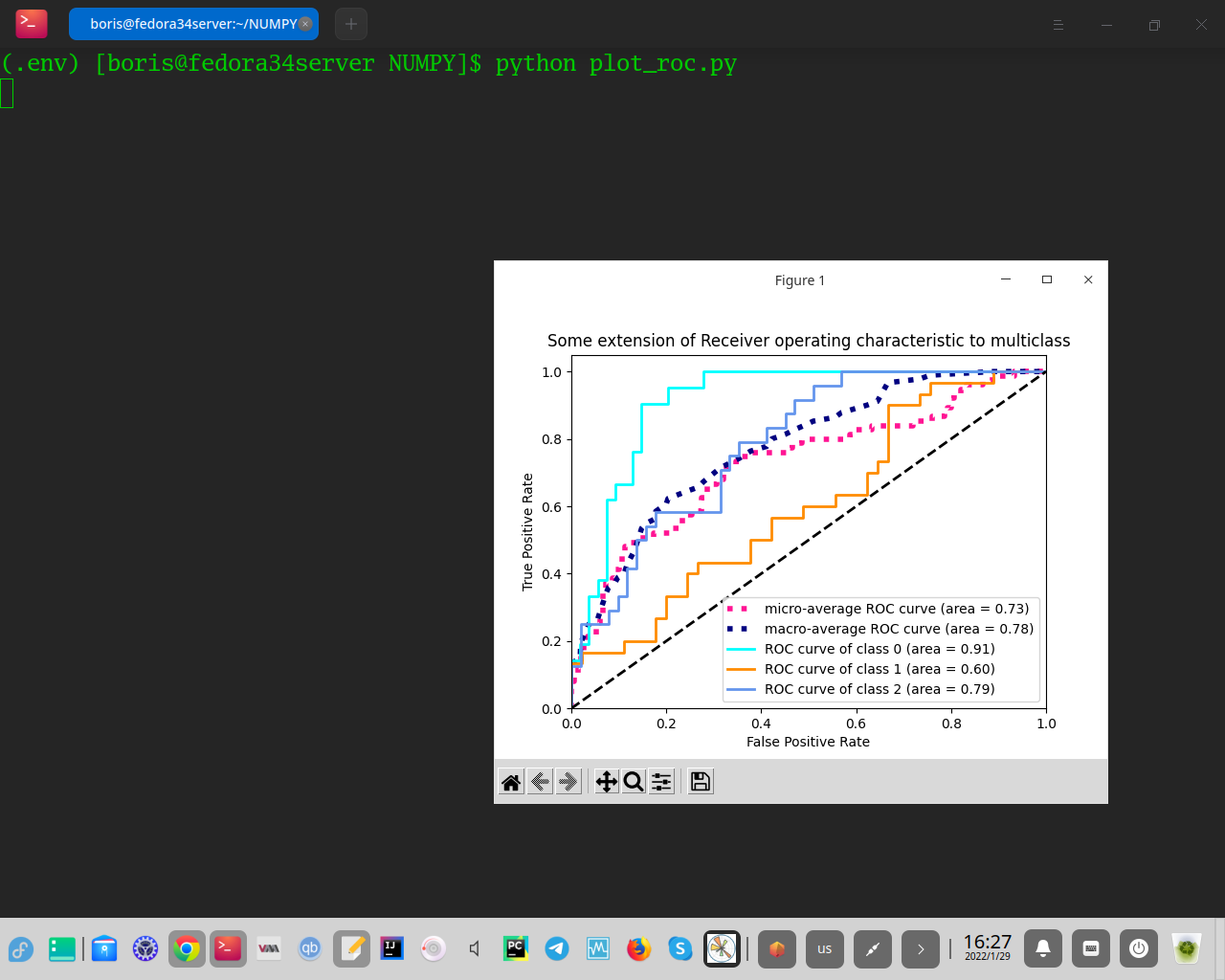
plt.figure()
plt.plot(
fpr["micro"],
tpr["micro"],
label="micro-average ROC curve (area = {0:0.2f})".format(roc_auc["micro"]),
color="deeppink",
linestyle=":",
linewidth=4,
)
plt.plot(
fpr["macro"],
tpr["macro"],
label="macro-average ROC curve (area = {0:0.2f})".format(roc_auc["macro"]),
color="navy",
linestyle=":",
linewidth=4,
)
colors = cycle(["aqua", "darkorange", "cornflowerblue"])
for i, color in zip(range(n_classes), colors):
plt.plot(
fpr[i],
tpr[i],
color=color,
lw=lw,
label="ROC curve of class {0} (area = {1:0.2f})".format(i, roc_auc[i]),
)
plt.plot([0, 1], [0, 1], "k--", lw=lw)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel("False Positive Rate")
plt.ylabel("True Positive Rate")
plt.title("Some extension of Receiver operating characteristic to multiclass")
plt.legend(loc="lower right")
[plt.show](http://plt.show)()
# %%
# Area under ROC for the multiclass problem
# .........................................
# The :func:`sklearn.metrics.roc_auc_score` function can be used for
# multi-class classification. The multi-class One-vs-One scheme compares every
# unique pairwise combination of classes. In this section, we calculate the AUC
# using the OvR and OvO schemes. We report a macro average, and a
# prevalence-weighted average.
y_prob = classifier.predict_proba(X_test)
macro_roc_auc_ovo = roc_auc_score(y_test, y_prob, multi_class="ovo", average="macro")
weighted_roc_auc_ovo = roc_auc_score(
y_test, y_prob, multi_class="ovo", average="weighted"
)
macro_roc_auc_ovr = roc_auc_score(y_test, y_prob, multi_class="ovr", average="macro")
weighted_roc_auc_ovr = roc_auc_score(
y_test, y_prob, multi_class="ovr", average="weighted"
)
print(
"One-vs-One ROC AUC scores:\n{:.6f} (macro),\n{:.6f} "
"(weighted by prevalence)".format(macro_roc_auc_ovo, weighted_roc_auc_ovo)
)
print(
"One-vs-Rest ROC AUC scores:\n{:.6f} (macro),\n{:.6f} "
"(weighted by prevalence)".format(macro_roc_auc_ovr, weighted_roc_auc_ovr)
)Стадия выполнения

(.env) [boris@fedora34server NUMPY]$ python plot_roc.py
One-vs-One ROC AUC scores:
0.698586 (macro),
0.665839 (weighted by prevalence)
One-vs-Rest ROC AUC scores:
0.698586 (macro),
0.665839 (weighted by prevalence)