Как решить проблему исчезновения и расширения градиента в машинном обучении?
ПрограммированиеМашинное обучениеDeep learning
Анонимный вопросМашинное обучение и Нейронные сети
· 10,7 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 3 февр 2022
Нейронные сети обучаются с помощью стохастического градиентного спуска.
Это включает в себя сначала вычисление ошибки прогнозирования, сделанной моделью, и использование ошибки для оценки градиента, используемого для обновления каждого веса в сети, чтобы в следующий раз было сделано меньше ошибок. Этот градиент ошибки распространяется обратно по сети от выходного слоя к входному слою.
Желательно обучать нейронные сети со многими слоями, так как добавление большего количества слоев увеличивает пропускную способность сети, делая ее способной изучать большой набор обучающих данных и эффективно представлять более сложные функции отображения от входов к выходам. Проблема с обучающими сетями со многими слоями (например, глубокими нейронными сетями) заключается в том, что градиент резко уменьшается по мере его распространения в обратном направлении по сети. Ошибка может быть настолько мала к тому времени, когда она достигает слоев, близких к входным данным модели, что она может иметь очень незначительный эффект. Таким образом, эта проблема называется проблемой «исчезающих градиентов». Исчезающие градиенты затрудняют понимание того, в каком направлении должны измениться параметры, чтобы улучшить функцию стоимости…
================================
На самом деле градиент ошибки может быть нестабильным в глубоких нейронных сетях и не только исчезать, но и взрываться, когда градиент экспоненциально увеличивается по мере его распространения в обратном направлении по сети. Это называется проблемой «взрывающегося градиента».
=================================
Термин исчезающий градиент относится к тому факту, что в сети с прямой связью (FFN) сигнал ошибки с обратным распространением обычно уменьшается (или увеличивается) экспоненциально в зависимости от расстояния от конечного слоя.
Исчезающие градиенты представляют собой особую проблему с рекуррентными нейронными сетями, поскольку обновление сети включает развертывание сети для каждого входного временного шага, что фактически создает очень глубокую сеть, требующую обновления веса. Скромная рекуррентная нейронная сеть может иметь от 200 до 400 входных временных шагов, что концептуально приводит к очень глубокой сети.
Проблема исчезающих градиентов может проявляться в многослойном персептроне медленной скоростью улучшения модели во время обучения и, возможно, преждевременной конвергенцией, например. дальнейшее обучение не приводит к дальнейшему улучшению. Проверяя изменения весов во время обучения, мы увидим, что больше изменений (то есть больше обучения) происходит в слоях, близких к выходному слою, и меньше изменений происходит в слоях, близких к входному слою.
Существует множество методов, которые можно использовать для уменьшения влияния проблемы исчезающих градиентов для нейронных сетей с прямой связью, в первую очередь альтернативные схемы инициализации весов и использование альтернативных функций активации.
Были изучены и применены различные подходы к обучению глубоких сетей (как с прямой связью, так и рекуррентные) [в целях устранения исчезающих градиентов], такие как предварительное обучение, лучшее случайное начальное масштабирование, лучшие методы оптимизации, специальные архитектуры, ортогональная инициализация и т.д.
Было предложено и исследовано множество исправлений и обходных путей, таких как альтернативные схемы инициализации веса, неконтролируемое предварительное обучение, послойное обучение и варианты градиентного спуска. Возможно, наиболее распространенным изменением является использование выпрямленной линейной функции активации, которая стала новой функцией по умолчанию, вместо гиперболической касательной функции активации, которая использовалась по умолчанию в конце 1990-х и 2000-х годах.
После этого постинга Вы будете знать следующее:
Проблема исчезающих градиентов ограничивает развитие глубоких нейронных сетей с классически популярными функциями активации, такими как гиперболический тангенс.
Как исправить глубокую нейронную сеть Multilayer Perceptron для классификации с использованием ReLU и инициализации веса He.
Как использовать TensorBoard для диагностики проблемы исчезающего градиента и подтверждения влияния ReLU на улучшение потока градиентов в модели.
Здесь мы более подробно рассмотрим использование альтернативной схемы инициализации весов и функции активации, позволяющей обучать более глубокие модели нейронных сетей.
========================================
В качестве основы для нашего исследования мы будем использовать очень простую задачу двухклассовой или бинарной классификации.
Класс scikit-learn предоставляет функцию make_circles(), которую можно использовать для создания задачи бинарной классификации с заданным количеством выборок и статистическим шумом.
Каждый пример имеет две входные переменные, которые определяют координаты x и y точки на двумерной плоскости. Точки расположены в двух концентрических окружностях (у них один и тот же центр) для двух классов.Количество точек в наборе данных задается параметром, половина из которых будет взята из каждого круга. Гауссовский шум можно добавить при выборке точек с помощью аргумента «шум», который определяет стандартное отклонение шума, где 0,0 означает отсутствие шума или точки, нарисованные точно из кругов. Начальное значение для генератора псевдослучайных чисел можно указать с помощью аргумента «random_state», который позволяет выбирать одни и те же точки при каждом вызове функции.В приведенном ниже примере генерируется 1000 примеров из двух кругов с шумом и значением 1 для заполнения генератора псевдослучайных чисел.Мы можем создать график набора данных, отобразив координаты x и y входных переменных (X) и раскрасив каждую точку значением класса (0 или 1).
Полный пример приведен ниже.
=================

При выполнении примера создается график, показывающий 1000 сгенерированных точек данных со значением класса каждой точки, используемым для окрашивания каждой точки. Мы можем видеть, что точки для класса 0 синие и представляют собой внешний круг, а точки для класса 1 оранжевые и представляют внутренний круг.
Статистический шум сгенерированных выборок означает, что между двумя кругами есть некоторое перекрытие точек, что добавляет некоторой неоднозначности задаче, делая ее нетривиальной. Это желательно, поскольку нейронная сеть может выбрать одно из многих возможных решений для классификации точек между двумя кругами и всегда делать некоторые ошибки. Теперь, когда мы определили проблему как основу для нашего исследования, мы можем заняться разработкой модели для ее решения.
==========================================
Многослойная модель персептрона для задачи двух кругов
Мы можем разработать модель многослойного персептрона для решения проблемы двух кругов.
Это будет простая модель нейронной сети с прямой связью, спроектированная так, как нас учили в конце 1990-х и начале 2000-х годов.
Во-первых, мы создадим 1000 точек данных из задачи двух кругов и перемасштабируем входные данные в диапазоне [-1, 1]. Данные почти уже в этом диапазоне, но мы обязательно уточним.Обычно мы подготавливаем масштабирование данных с использованием обучающего набора данных и применяем его к тестовому набору данных. Чтобы упростить задачу в этом руководстве, мы будем масштабировать все данные вместе, прежде чем разделить их на обучающие и тестовые наборы.
Теперь, когда мы увидели, как разработать классическую MLP, используя функцию активации tanh для задачи двух кругов, мы можем рассмотреть возможность изменения модели, чтобы иметь гораздо больше скрытых слоев. Более глубокая модель MLP для задачи двух кругов. Традиционно разработка глубоких моделей многослойного персептрона была сложной задачей.
Глубокие модели, использующие функцию активации гиперболического тангенса, не легко обучаются, и во многом эта плохая производительность связана с проблемой исчезающего градиента.
Мы можем попытаться исследовать это, используя модель MLP, разработанную в предыдущем разделе.
Количество скрытых слоев можно увеличить с 1 до 5; Например:
Полный пример более глубокого MLP приведен ниже.


При запуске примера сначала печатается производительность подходящей модели в наборах данных тренинга и теста.
В этом случае мы видим, что производительность довольно низкая как на обучающих, так и на тестовых наборах, достигая точности около 50%-70%. Это говорит о том, что сконфигурированная модель не могла изучить проблему или обобщить решение.
=================================
Более глубокая модель MLP с ReLU для задачи двух кругов
Выпрямленная линейная функция активации заменила гиперболическую тангенциальную функцию активации в качестве нового предпочтительного значения по умолчанию при разработке сетей многослойного персептрона, а также других типов сетей, таких как CNN. Это связано с тем, что функция активации выглядит и действует как линейная функция, что упрощает обучение и снижает вероятность насыщения, но на самом деле является нелинейной функцией, заставляющей отрицательные входные данные принимать значение 0. Это заявлено как один из возможных подходов. для решения проблемы исчезающих градиентов при обучении более глубоких моделей.
При использовании выпрямленной линейной функции активации (или для краткости ReLU) рекомендуется использовать схему инициализации веса He. Мы можем определить MLP с пятью скрытыми слоями, используя инициализацию ReLU и He, перечисленную ниже.


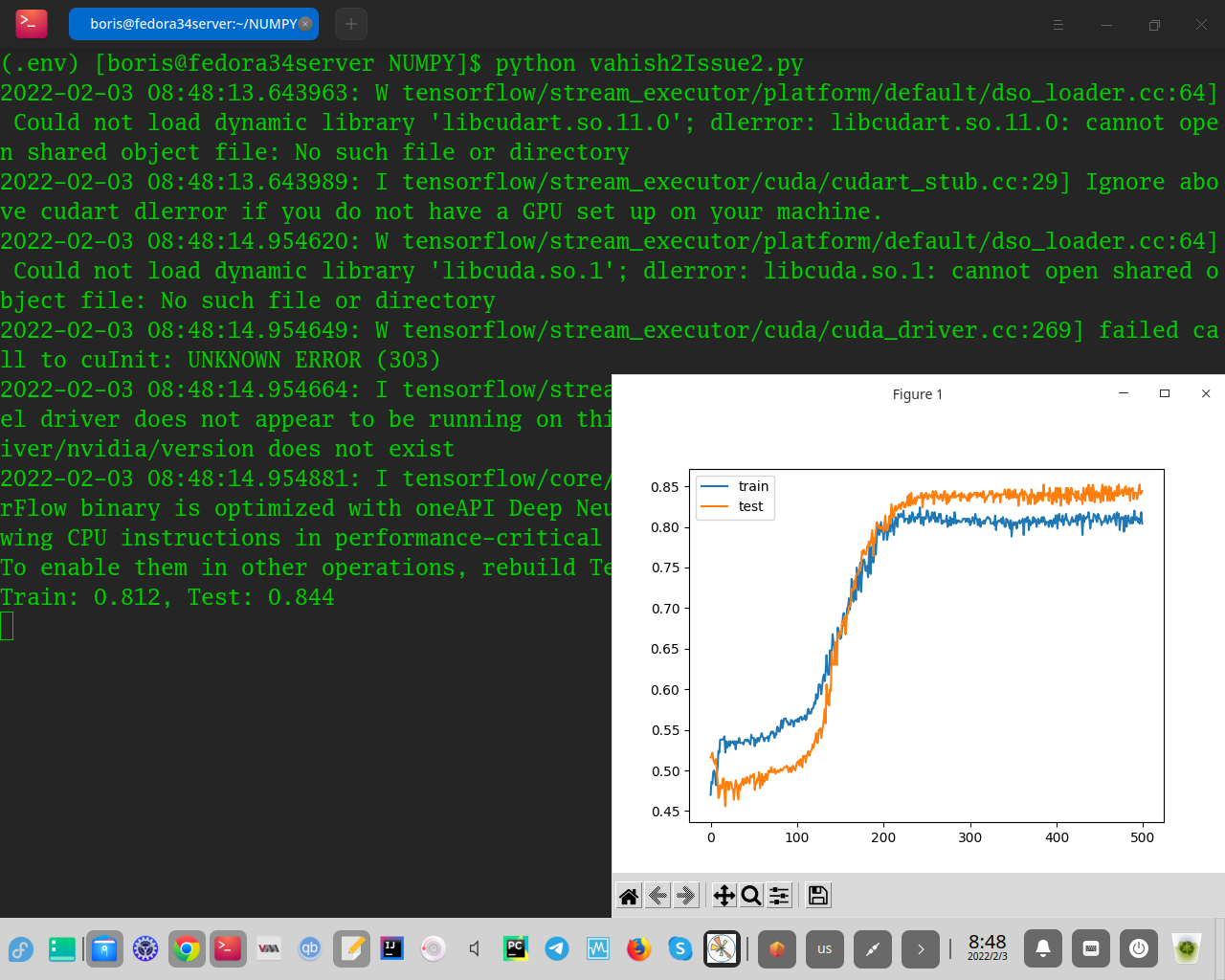
В этом случае мы видим, что это небольшое изменение позволило модели изучить проблему, достигнув точности около 84% для обоих наборов данных, превзойдя многослойную модель с использованием функции активации tanh. Причем этот показатель стабилен.
========================================
Также создается линейный график точности модели на обучающих и тестовых наборах в течение эпох обучения. Сюжет показывает совершенно другую динамику, чем то, что мы видели до сих пор.
========================================
UPDATE 3/02/22 MSK 17:52
========================================
Попытка запуска TensorBoard web interface
- Запуск Code 6 из https://informatics-ege.blogspot.com/2022/02/vanishing-gradients-problem-using-relu.html в первом терминале
2.Во втором терминале
$ tensorboard --logdir path/to/logs
Действие выше отлично от рекомендованного
Получаем TensorBoard web interface на порту 6006



=========================================
Плоты строились на Линукс Сервере без GPU , что нехорошо TensorFlow
и дает сообщение -
2022-02-03 09:01:59.221801: I tensorflow/core/platform/cpu_feature_guard.cc:151] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
========================================
Это вполне возможно указав в настройках билда работать только с CPU
или поставить нормальную видео карту - новая NVIDIA GeForce должна убрать проблемы с CUDA
CUDA® — это платформа параллельных вычислений и модель программирования, которая позволяет значительно повысить производительность вычислений за счет использования мощности графического процессора (GPU). Приложения, используемые в астрономии, биологии, химии, физике, интеллектуальном анализе данных, производстве, финансах и других областях, требующих больших вычислительных ресурсов, все чаще используют CUDA для реализации преимуществ ускорения GPU.
Как подавить сообщения Пайтон о том , что при наличии GPU производительность может быть выше за счет AVX2 FMA... Читать дальше