Борис Державец3,1 K
Data science
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 19 нояб 2021
============================================
Создание собственного механизма обратного распространения ошибки для глубоких нейронных сетей
============================================
В этом разделе я познакомлю вас с простым многослойным персептроном и выведу алгоритм обратного распространения ошибки. Есть много способов получить это, но я начну с подхода минимизации ошибок, который в основном описывает соответствие нейронной сети f (x, θ) отклонением от известной цели y. Архитектура, которую мы будем решать, показана на изображении ниже, где у нас есть два скрытых слоя. Мы придерживаемся этого для простоты. Мы также будем использовать только один результат вместо нескольких, но он легко поддается обобщению.
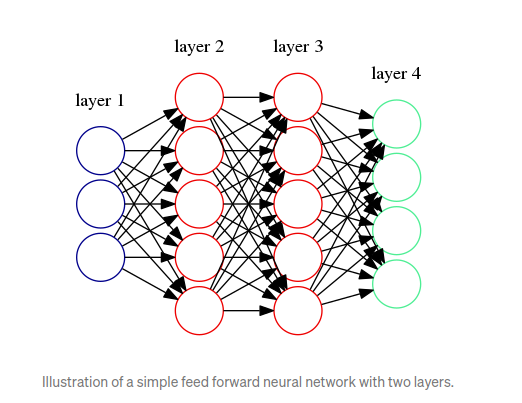
Вместо того, чтобы представлять нашу сеть графически, мы сделаем здесь более формальное представление, в котором функциональная форма будет указана математически. В основном функциональная форма будет
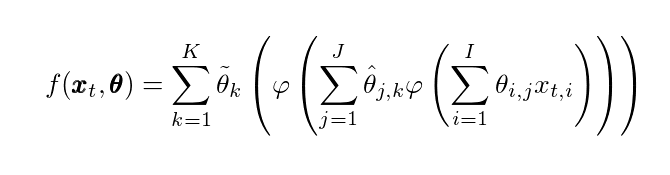
где жирным шрифтом обозначены векторы. Функция φ (s) = 1/(1 + exp (-a*s)) - это сигмовидная функция активации с гиперпараметром a, который мы не будем настраивать или о котором не будем заботиться в этом введении. Небольшое замечание, игнорирование параметра "a" здесь действительно глупо, поскольку это коренным образом изменит обучение этой сети. Единственная причина, по которой я позволяю себе это делать, состоит в том, что сейчас это выходит за рамки возможностей охватить это. Чтобы обучить нейронную сеть, нам нужно обновить параметры в соответствии с тем, насколько они влияют на ошибку, которую мы видим. Эту ошибку можно определить так для проблемы, подобной регрессии, для точки данных (xₜ, yₜ).
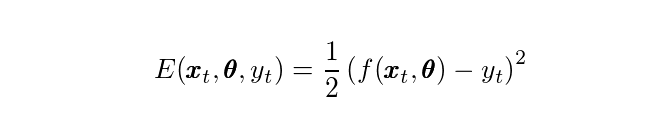
Если мы посмотрим на второй последний слой, мы просто обновим параметры в соответствии со следующим правилом
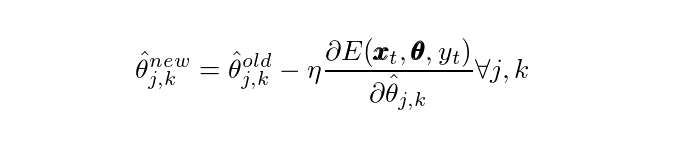
для каждой новой точки данных. Это называется стохастическим градиентным спуском (SGD). Вы можете много прочитать об этом во многих местах, поэтому я не буду углубляться в это здесь. Достаточно сказать, что этот процесс может повторяться для каждого параметра в каждом слое. Итак, печально известный алгоритм обратного распространения ошибки - это просто приложение для обновления ваших параметров с помощью частной производной ошибки по этому самому параметру. Сделайте частные производные для себя сейчас и посмотрите, насколько легко вы сможете их вывести. Небольшой трюк, который вы можете использовать, - это понять, что φ‘(s) = φ(s)*(1-φ(s)), где я использовал простое обозначение для производной. Вот хороший учебник о том, как сделать это численно.
Я перевел ту часть оригинальной статьи , которая показалась мне наиболее интересной. В целом статья требует знание технического Английского, как и последняя ссылка тоже.
1,1 K
Комментировать ответ…Комментировать…
Василий Банников558
Программирование
Если под производной понимается та самая штука из математики, которая определяет рост какой-либо функции, то очевидно, что это можно применить в анализе данных, но никак нельзя применить в информационной безопасности. (если можно - значит я что-то не знаю про ИБ)
Например, у тебя есть данные по общему капиталу компании в определённые периоды времени.
Но тебе нужно... Читать далее
563
Наконец-то. Спасибо! Мне нужно было что-то за что я мог бы зацепиться. Теперь все понятно
Комментировать ответ…Комментировать…
Мари Годар25
Экономика
В анализе данных без производных никак!
Правда, там одними ими не обходится…
Например, решая задачу минимизации/максимизации (издержек/прибыли компании и п.) используется метод множителей Лагранжа, а для него нужны производные.
Также они нужны для популярного метода машинного обучения градиентный бустинг.
Помимо этого, производная может неявно использоваться в... Читать далее
404
Комментировать ответ…Комментировать…