Как правильно выбрать параметр CV в LassoCv?
ОбразованиеПрограммирование+3
Анонимный вопросData Science
· 5,6 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 11 мар 2022
При оценке различных настроек («гиперпараметров») для оценщиков, таких как например параметр C, который должен быть установлен вручную для SVM, все еще существует риск переобучения в тестовом наборе, поскольку параметры можно настраивать до тех пор, пока оценщик не будет работать оптимально. Таким образом, знания о тестовом наборе могут «просочиться» в модель, а метрики оценки больше не сообщают о производительности обобщения. Чтобы решить эту проблему, еще одна часть набора данных может быть представлена
в виде так называемого «проверочного набора»: обучение продолжается на обучающем наборе, после чего выполняется оценка на проверочном наборе, и когда эксперимент кажется успешным , окончательную оценку можно выполнить на тестовом наборе.
в виде так называемого «проверочного набора»: обучение продолжается на обучающем наборе, после чего выполняется оценка на проверочном наборе, и когда эксперимент кажется успешным , окончательную оценку можно выполнить на тестовом наборе.
==================================
Однако, разбивая доступные данные на три-пять наборов, мы резко сокращаем количество выборок, которые можно использовать для обучения модели, а результаты могут зависеть от конкретного случайного выбора пары наборов (обучение, проверка).
Мера производительности, о которой сообщает k-кратная перекрестная проверка, представляет собой среднее значение значений, вычисленных в цикле. Этот подход может быть дорогостоящим в вычислительном отношении, но не тратит слишком много данных (как в случае фиксации произвольного набора проверки), что является большим преимуществом в таких задачах, как обратный вывод, когда количество выборок очень мало.
=================================
Решением этой проблемы является процедура, называемая перекрестной проверкой (сокращенно CV).
Тестовый набор по-прежнему должен храниться для окончательной оценки, но проверочный набор больше не нужен при выполнении CV. В базовом подходе, называемом k-fold CV, обучающая выборка разбивается на k меньших наборов (другие подходы описаны ниже, но в целом следуют тем же принципам). Для каждой из k «складок» выполняется следующая процедура:
Модель обучается с использованием складок в качестве обучающих данных; полученная модель проверяется на оставшейся части данных (т.е. Она используется в качестве тестового набора для вычисления показателя производительности, такого как точность).
Мера производительности, о которой сообщает k-кратная перекрестная проверка, представляет собой среднее значение значений, вычисленных в цикле. Этот подход может быть дорогостоящим в вычислительном отношении, но не тратит слишком много данных (как в случае фиксации произвольного набора проверки), что является большим преимуществом в таких задачах, как обратный вывод, когда количество выборок очень мало.

Кросс-валидатор K-Folds - Предоставляет индексы обучения/тестирования для разделения данных в наборах обучения/тестирования. Разделить набор данных на k последовательных сгибов (без перетасовки по умолчанию). Каждая складка затем используется один раз для проверки, в то время как оставшиеся k - 1 складки образуют обучающий набор.
Параметры
n_splits, по умолчанию = 5
Количество складок. Должно быть не менее 2.
Изменено в версии 0.22: значение по умолчанию n_splits изменено с 3 на 5.
shufflebool, по умолчанию = False
Следует ли перемешивать данные перед разделением на пакеты. Обратите внимание, что образцы в каждом разделении не будут перемешиваться.
random_stateint, экземпляр RandomState или None, по умолчанию = None.
Когда shuffle имеет значение True, random_state влияет на порядок индексов, который контролирует случайность каждого сгиба. В противном случае этот параметр не действует. Передайте int для воспроизводимого вывода через несколько вызовов функций
Выполним Code 1 из https://informatics-ege.blogspot.com/2022/03/run-lassocv-for-cross-validation-on.html

Установим n_splitinst = 10
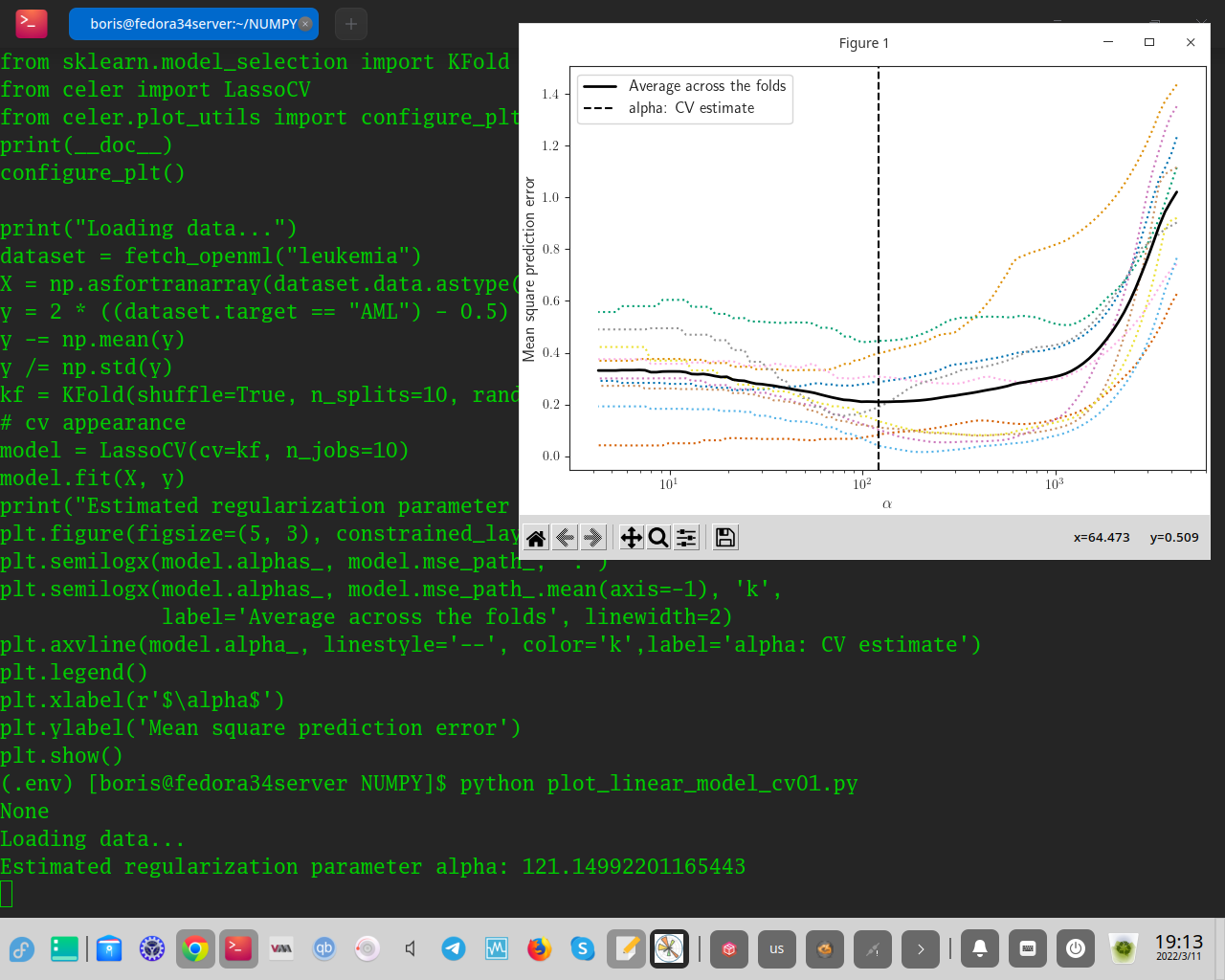
Для данного примера уменьшение меры средне-квадратичной ошибки 0.10-0.15 не более. Тестированы значения n_splits = 5,10,15,20 ( максимум допустимый набором 72 ). Shuffle установлен в True.
Источник
Что есть "Celer"