Что такое предельная ошибка выборки и доверительный интервал?
ПрограммированиеData science+3
Анонимный вопросData Science
· 10,3 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 25 мар 2022
Что такое погрешность?
=====================
Погрешность — это информация, которая предоставляется вместе с результатами исследования, например опроса, опроса или научного исследования. Вы узнаете его, потому что он выражается знаком плюс и минус вместе, например. + или -1%. Исследователи используют это, чтобы предоставить дополнительную информацию, которая поможет вам интерпретировать их результаты и понять, как проводилось исследование. Цифра говорит вам о том, что истинный результат может отличаться от представленного процентного значения, и насколько больше или меньше заявленного процента может быть реальность. Предел погрешности обеспечивает более четкое понимание того, что означает оценка характеристики населения, полученная в ходе обследования. Плюс-минус 2 процентных пункта означает, что если мы зададим этот вопрос, используя простую случайную выборку 100 раз, 95 из этих раз будет получено оценочное значение плюс-минус 2 пункта. Чем больше ваша случайная выборка (чем больше ответов вы получите), тем меньше будет ваша погрешность и тем больше у вас будет уверенности в том, что результаты вашей выборки надежны.
Когда используется погрешность?
Погрешность используется, когда у вас есть случайная или вероятностная выборка.Это означает, что респонденты были выбраны случайным образом из вашей совокупности в целом, и каждый член совокупности имеет известную ненулевую вероятность быть включенным.
Неуместно, если выборка была выбрана неслучайным образом, например, когда вы используете добровольную исследовательскую панель.
========================
Выборка исследовательской панели обычно представляет собой квотную выборку, в которой участники отбираются, потому что они обладают определенными характеристиками. Кроме того, респонденты добровольно участвуют в панели в обмен на льготы, поэтому они не выбираются случайным образом из общей численности населения.Таким образом, хотя это широко известный термин, он имеет особое применение в опросах и не всегда будет иметь отношение к данным вашего исследования рынка.
========================
Вот пара сценариев:
У спортивной команды есть полный список всех, кто приобрел билеты на их игры в прошлом году. Если они случайным образом отберут выборку из этого населения для опроса, они смогут рассчитать погрешность процента людей, которые сообщили, что являются фанатами команды.
========================
Организация имеет полный список сотрудников. Они опрашивают простую случайную выборку этих сотрудников о том, предпочитают ли они дополнительный день отпуска или небольшую премию. Они могут сообщить о погрешности в процентах, предпочитающих каждый вариант.
=========================
Что такое доверительный интервал?
=========================
Доверительный интервал (ДИ) — это диапазон значений, включающий значение генеральной совокупности в пределах степени достоверности.
Значения обычно отображаются в результатах в виде процентного значения, когда среднее значение генеральной совокупности находится между нижним и верхним пределом. Исследователи используют CI, чтобы измерить, насколько точно выборка опроса напоминает генеральную совокупность. Это связано с тем, что практически невозможно найти выборку, которая на 100% соответствует характеристикам всего населения. Исследователи могут выбрать доверительный интервал любого уровня, но наиболее распространенным является 95-процентный доверительный интервал. Это означает, что исследователи могут быть на 95% уверены, что результаты содержат фактическое среднее значение для всего населения. Это можно продемонстрировать с помощью нормального распределения:
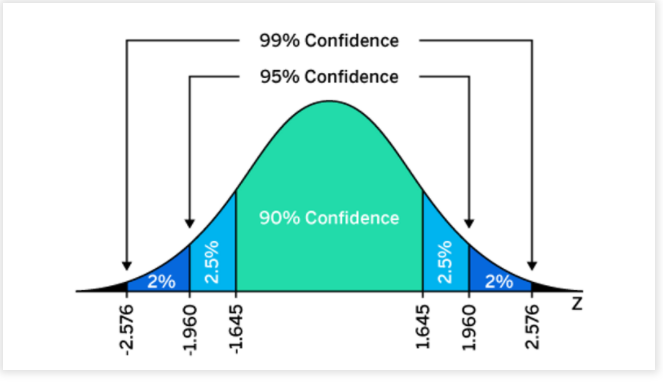
Используя приведенный выше график, вы можете видеть, что если вероятность среднего значения генеральной совокупности составляет от 1,96 до -1,96 стандартных отклонений (иногда называемая показателем z), среднее значение выборки составляет 95% (отсюда 95% ДИ).
Это наиболее распространенная отраслевая формула для расчета CI. Однако, когда цена ошибки чрезвычайно высока, т.е. на карту поставлено многомиллионное решение, доверительный интервал должен быть небольшим. Это можно сделать, увеличив размер выборки.
==============================
Как рассчитать погрешность?
==============================
Погрешность рассчитывается по формуле -
Записи в таблице представляют двусторонние значения "p" для Z-статистики.
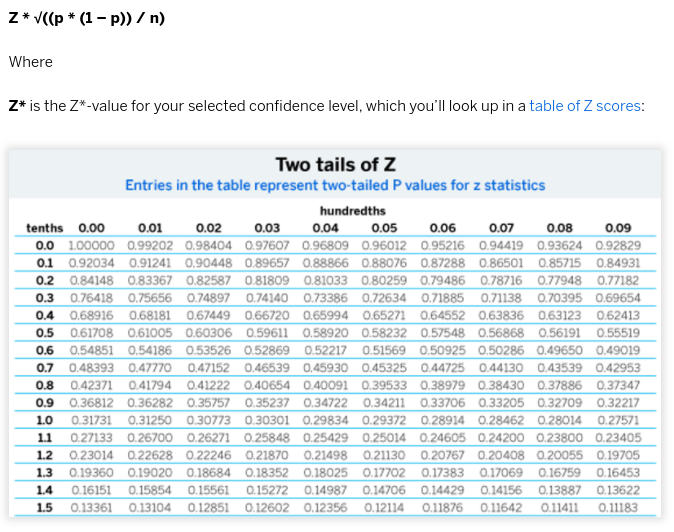
Tables of Z scores есть линк.
========================
p - доля выборки
n - размер выборки
Доля выборки — это число в выборке, которое имеет интересующую вас характеристику. Это десятичное число, представляющее процент, поэтому, когда вы выполняете расчет, оно выражается в сотых долях. Для доли выборки 5% это будет 0,05. Наиболее часто используемый уровень достоверности составляет 95%, поэтому мы будем использовать его для примера расчета. Значение Z* для уровня достоверности 95% составляет 1,96.
=========================
Представьте, что вы занимаетесь опросом своих текущих клиентов. Вы провели исследование со случайно выбранной выборкой из 1000 человек из вашего списка CRM. Результаты говорят вам, что из этой 1000 клиентов 52% (520 человек) довольны своей последней покупкой, а 48% (480 человек) — нет.
Вы хотите добавить к этим результатам погрешность, когда будете сообщать о них своим акционерам. Предположим, вам нужен уровень достоверности 95%, поэтому значение z*, с которым вы работаете, снова равно 1,96. Число клиентов, довольных своей последней покупкой, составило 520, так что это число вы будете использовать для расчета доли выборки. 520 (б) / 1000 (н) = 0,52
1-p равно 0,48
0,52 (p) х 0,48 (1-p) = 0,2496
0,2496 / 1000 = 0,0002496
Квадратный корень из 0,0002496 = 0,0157987.
0,0157987 x 1,96 (значение z*) = 0,0309654, или, другими словами, 3,1% (при округлении в большую сторону).
===========================
Теперь вы можете с уверенностью 95 % сообщить, что 52 % ваших клиентов были довольны своей последней покупкой, + или – 3,1 %.
============================
Есть несколько условий для использования этой формулы. Они есть:
n x p должно быть равно 10 или больше
n x (1-p) должно быть равно 10 или больше
Обычно в опросных исследованиях участвует довольно большое количество людей в выборке, поэтому, если у вас очень маленькая выборка или доля выборки в вашей выборке очень мала, проблем не возникнет. Если вы получаете числа ниже 10 для любой из этих проверок, вам может потребоваться увеличить размер выборки.