Объясните наиболее простым способом принцип работы MapReduce?
ПрограммированиеData science+3
Алена КаменецкихData Science
· 3,8 K
MapReduce - это модуль обработки в проекте Apache Hadoop. Hadoop - это платформа, созданная для обработки больших данных с использованием сети компьютеров для хранения и обработки данных.Что так привлекательно в Hadoop, так это то, что доступных выделенных серверов достаточно для работы кластера. Для обработки данных вы можете использовать недорогое потребительское оборудование. Hadoop отличается высокой масштабируемостью. Вы можете начать с одной машины, а затем расширить свой кластер до бесконечного числа серверов. Двумя основными компонентами этой программной библиотеки по умолчанию являются:
====================================
HDFS - распределенная файловая система Hadoop
MapReduce
====================================
Что такое Hadoop MapReduce?
Модель программирования Hadoop MapReduce упрощает обработку больших данных, хранящихся в HDFS.
Используя ресурсы нескольких взаимосвязанных машин, MapReduce эффективно обрабатывает большие объемы структурированных и неструктурированных данных.

Используя ресурсы нескольких взаимосвязанных машин, MapReduce эффективно обрабатывает большие объемы структурированных и неструктурированных данных.До Spark и других современных фреймворков эта платформа была единственным игроком в области распределенной обработки больших данных.MapReduce назначает фрагменты данных по узлам в кластере Hadoop. Цель состоит в том, чтобы разбить набор данных на фрагменты и использовать алгоритм для одновременной обработки этих фрагментов. Параллельная обработка на нескольких машинах значительно увеличивает скорость обработки даже петабайт данных.
Приложения для распределенной обработки данных
Эта структура позволяет писать приложения для распределенной обработки данных. Обычно большинство программистов используют Java, поскольку Hadoop основан на Java.Однако вы можете писать приложения MapReduce на других языках, таких как Ruby или Python. Независимо от того, какой язык может использовать разработчик, не нужно беспокоиться об оборудовании, на котором работает кластер Hadoop.
Масштабируемость
В инфраструктуре Hadoop могут использоваться серверы корпоративного уровня, а также обычное оборудование. Создатели MapReduce думали о масштабируемости. При добавлении дополнительных машин нет необходимости переписывать приложение. Просто измените настройки кластера, и MapReduce продолжит работать без сбоев. Что делает MapReduce настолько эффективным, так это то, что он работает на тех же узлах, что и HDFS. Планировщик назначает задачи узлам, на которых уже находятся данные. Такой подход увеличивает доступную пропускную способность в кластере.
=======================
Как работает MapReduce
=======================
На высоком уровне MapReduce разбивает входные данные на фрагменты и распределяет их по разным машинам.
Входные фрагменты состоят из пар ключ-значение. Задачи параллельной карты обрабатывают фрагментированные данные на машинах в кластере. Выходные данные сопоставления затем служат входными данными для этапа сокращения. Задача уменьшения объединяет результат в вывод конкретной пары "ключ-значение" и записывает данные в HDFS.
Распределенная файловая система Hadoop обычно работает на том же наборе компьютеров, что и программное обеспечение MapReduce. Когда инфраструктура выполняет задание на узлах, которые также хранят данные, время выполнения задач значительно сокращается.
Базовая терминология Hadoop MapReduce
Как мы упоминали выше, MapReduce - это уровень обработки в среде Hadoop. MapReduce работает с задачами, связанными с работой. Идея состоит в том, чтобы решить один большой запрос, разделив его на более мелкие части.
JobTracker и TaskTracker
На заре Hadoop (версия 1) демоны JobTracker и TaskTracker выполняли операции в MapReduce. В то время кластер Hadoop мог поддерживать только приложения MapReduce.
JobTracker контролировал распределение запросов приложений на вычислительные ресурсы в кластере. Поскольку он следил за выполнением и состоянием MapReduce, он находился на главном узле.
TaskTracker обрабатывал запросы, поступающие от JobTracker. Все трекеры задач были распределены по подчиненным узлам в кластере Hadoop.
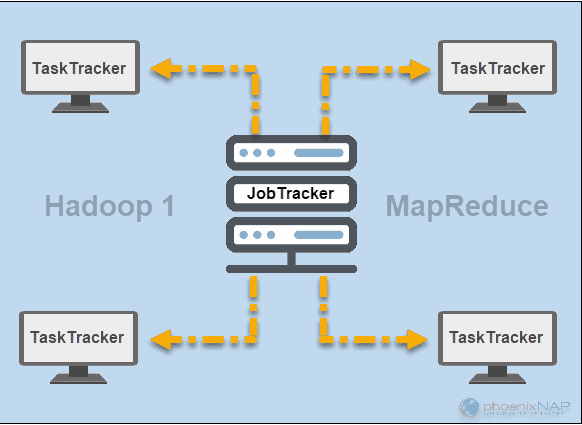
Позже, в Hadoop версии 2 и выше, YARN стал основным диспетчером ресурсов и расписания. Отсюда и название «Еще один менеджер ресурсов». Yarn также работал с другими фреймворками для распределенной обработки в кластере Hadoop.
MapReduce Job
Задание MapReduce - это основная единица работы в процессе MapReduce. Это задание, которое необходимо выполнить процессами Map и Reduce. Задание делится на более мелкие задачи по кластеру машин для более быстрого выполнения. Задачи должны быть достаточно большими, чтобы оправдать время обработки задачи. Если вы разделите задание на необычно маленькие сегменты, общее время, затрачиваемое на подготовку разделов и создание задач, может перевесить время, необходимое для фактического вывода задания.
Задача MapReduce
Задания MapReduce имеют два типа задач.
Задача Отображения (Map) - это отдельный экземпляр приложения MapReduce. Эти задачи определяют, какие записи из блока данных обрабатывать. Входные данные разделяются и анализируются параллельно на назначенных вычислительных ресурсах в кластере Hadoop. Этот шаг задания MapReduce подготавливает выходные данные пары <ключ, значение> для шага сокращения.
==============================
Задача уменьшения (Reduce) обрабатывает выходные данные задачи карты. Как и на этапе карты, все задачи сокращения выполняются одновременно и работают независимо. Данные агрегируются и объединяются для получения желаемого результата. Конечным результатом является сокращенный набор пар <ключ, значение>, которые MapReduce по умолчанию сохраняет в HDFS.

Этапы Map и Reduce состоят каждая из двух частей.
Часть «Map» сначала занимается разделением входных данных, которые назначаются отдельным задачам карты. Затем функция сопоставления создает выходные данные в виде промежуточных пар ключ-значение.
Этап уменьшения (Reduce) включает в себя перетасовку и этап уменьшения. Перемешивание берет выходные данные карты и создает список связанных пар ключ-значение-список. Затем сокращение объединяет результаты перетасовки для получения окончательного результата, запрошенного приложением MapReduce.
Hadoop Map и Совместное сокращение работы
Как следует из названия, MapReduce обрабатывает входные данные в два этапа - Map и Reduce. Чтобы продемонстрировать это, мы будем использовать простой пример с подсчетом количества вхождений слов в каждый документ. Окончательный результат, который мы ищем: сколько раз слова Apache, Hadoop, Class и Track встречаются в сумме во всех документах. В целях иллюстрации примерная среда состоит из трех узлов. Входные данные содержат шесть документов, распределенных по кластеру. Здесь все будет просто, но в реальных условиях нет предела. У вас могут быть тысячи серверов и миллиарды документов.

1)Сначала на этапе сопоставления входные данные (шесть документов) разделяются и распределяются по кластеру (трем серверам). В этом случае каждая задача карты работает с разделением, содержащим два документа. Во время отображения нет связи между узлами. Они выступают самостоятельно.
===========================
2) Затем задачи карты создают пару <ключ, значение> для каждого слова. Эти пары показывают, сколько раз встречается слово. Слово - это ключ, а значение - его количество. Например, один документ содержит три из четырех слов, которые мы ищем: Apache 7 раз, Class 8 раз и Track 6 раз. Пары ключ-значение в выходных данных одной задачи карты выглядят следующим образом:
<apache, 7>
<класс, 8>
<трек, 6>
Этот процесс выполняется параллельно на всех узлах для всех документов и дает уникальный результат.
===========================
3) После завершения разделения входных данных и сопоставления выходы каждой задачи сопоставления перетасовываются. Это первый шаг этапа уменьшения. Поскольку мы ищем частоту появления четырех слов, существует четыре параллельных задачи Reduce. Задачи сокращения могут выполняться на тех же узлах, что и задачи карты, или они могут выполняться на любом другом узле.
Шаг перемешивания обеспечивает сортировку ключей Apache, Hadoop, Class и Track для шага сокращения. Этот процесс группирует значения по ключам в виде пар <ключ, список значений>.
==========================
4) На этапе уменьшения этапа уменьшения каждая из четырех задач обрабатывает <ключ, список-значений> для получения окончательной пары «ключ-значение». Задачи сокращения также выполняются одновременно и работают независимо.
В нашем примере из диаграммы задачи сокращения получают следующие индивидуальные результаты:
<apache, 22>
<Хадуп, 20>
<класс, 18>
<трек, 22>
==========================
5) Наконец, данные на этапе «Уменьшение» сгруппированы в один вывод. MapReduce теперь показывает нам, сколько раз слова Apache, Hadoop, Class и track появлялись во всех документах. По умолчанию агрегированные данные хранятся в HDFS.Пример, который мы использовали здесь, является основным. MapReduce выполняет гораздо более сложные задачи.Некоторые из вариантов использования включают:
Преобразование журналов Apache в значения, разделенные табуляцией (TSV).
Определение количества уникальных IP-адресов в данных веб-журнала.
Выполнение сложного статистического моделирования и анализа.
Запуск алгоритмов машинного обучения с использованием различных фреймворков, например Mahout.
===========================
Как разделы Hadoop сопоставляют входные данные
Разделитель отвечает за обработку вывода карты. После того, как MapReduce разбивает данные на части и назначает их задачам карты, платформа разделяет данные «ключ-значение». Этот процесс происходит до того, как будет произведен окончательный вывод задачи картографа.
MapReduce разделяет и сортирует вывод на основе ключа. Здесь все значения для отдельных ключей сгруппированы, и разделитель создает список, содержащий значения, связанные с каждым ключом. Отправляя все значения одного ключа одному и тому же редуктору, разделитель обеспечивает равное распределение вывода карты в редуктор.
============================
Проблема с обработкой больших данных заключалась в том, что традиционные инструменты не были готовы справиться с объемом и сложностью входных данных. Именно здесь в игру вступил Hadoop MapReduce.
============================
Преимущества использования MapReduce включают параллельные вычисления, обработку ошибок, отказоустойчивость, ведение журналов и создание отчетов. Эта статья стала отправной точкой в понимании того, как работает MapReduce и его основные концепции.