Как справиться с переобучением Деревьев Решений? Это сложно?
ПрограммированиеData science+3
Алена КаменецкихData Science
· 839
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 25 дек 2021
Переобучение - значительная практическая трудность для моделей дерева решений и многих других моделей прогнозирования.
Переобучение происходит, когда алгоритм обучения продолжает развивать гипотезы, которые уменьшают ошибку обучающего набора за счет повышенная погрешность тестового набора. Существует несколько подходов к предотвращению переобучения при построении деревьев решений.
=======================
Предварительная обрезка, при которой дерево перестает расти раньше, прежде чем оно идеально классифицирует обучающий набор.
Пост-обрезка, которая позволяет дереву идеально классифицировать обучающий набор, а затем выполнять пост-обрезку дерева.
=======================
Практически, второй подход - переобученные деревья после обрезки - более успешен, потому что нелегко точно оценить, когда следует прекратить рост дерева. Важным этапом обрезки дерева является определение критерия, который будет использоваться для определения правильного окончательного размера дерева, используя один из следующих методов:
=======================
Используйте отдельный набор данных из обучающего набора (называемый набором проверки), чтобы оценить эффект пост-отсечения узлов из дерева.
======================
Постройте дерево, используя обучающий набор, затем примените статистический тест, чтобы оценить, приведет ли сокращение или расширение конкретного узла к улучшению, выходящему за пределы обучающего набора.
Оценка погрешности
Проверка значимости (например, критерий хи-квадрат)
======================
Принцип минимальной длины описания: используйте явную меру сложности для кодирования обучающего набора и дерева решений, останавливая рост дерева, когда этот размер кодирования (размер (дерево) + размер (ошибочная классификация (дерево)) минимизирован.
======================
Первый метод - наиболее распространенный подход. В этом подходе доступные данные разделены на два набора примеров: обучающий набор, который используется для построения дерева решений, и набор проверки, который используется для оценки воздействия обрезки дерева. Второй способ - тоже распространенный подход. Здесь мы объясняем оценку ошибки и тест Chi2.

Частота ошибок в родительском узле составляет 0,46, и поскольку частота ошибок для его дочерних узлов (0,51) увеличивается с разбиением, мы не хотим оставлять дочерние узлы.
После обрезки с использованием теста Chi2. В тесте Chi2 мы составляем соответствующую таблицу частот и вычисляем значение Chi2 и его вероятность.
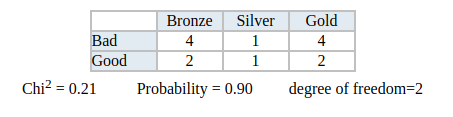
Если мы требуем, чтобы вероятность была меньше предела (например, 0,05), мы решаем не разбивать узел.