Что произойдет, если мы воспользуемся чрезмерной скоростью обучения?
Машинное обучениеИсследования+2
Анонимный вопросМашинное обучение и Нейронные сети
· 3,2 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 10 февр 2022
Мы будем использовать небольшую задачу классификации нескольких классов в качестве основы для демонстрации влияния скорости обучения на производительность модели.Класс scikit-learn предоставляет функцию make_blobs(), которую можно использовать для создания задачи классификации нескольких классов с заданным количеством выборок, входных переменных, классов и дисперсии выборок внутри класса.Задача имеет две входные переменные (для представления координат x и y точек) и стандартное отклонение 2,0 для точек в каждой группе. Мы будем использовать одно и то же случайное состояние (начальное число для генератора псевдослучайных чисел), чтобы всегда получать одни и те же точки данных.

При выполнении примера создается точечная диаграмма всего набора данных. Мы видим, что стандартное отклонение 2,0 означает, что классы не являются линейно разделимыми (разделимыми линией), что вызывает много неоднозначных моментов.Это желательно, поскольку означает, что проблема нетривиальна и позволит модели нейронной сети найти множество различных «достаточно хороших» возможных решений.
=====================================
Скорость обучения может быть самым важным гиперпараметром при настройке вашей нейронной сети. Поэтому очень важно знать, как исследовать влияние скорости обучения на производительность модели и построить интуитивное представление о динамике скорости обучения на поведении модели. Высокие скорости обучения приводят к нестабильности обучения, а маленькие скорости приводят к неудачам в обучении. Momentum может ускорить обучение, а графики скорости обучения могут помочь сблизить процесс оптимизации. Адаптивная скорость обучения может ускорить обучение и частично облегчить выбор скорости обучения и графика скорости обучения.
================================
Влияние скорости обучения и импульса В этом разделе мы разработаем модель многослойного персептрона (MLP), чтобы решить проблему классификации больших двоичных объектов и исследовать влияние различных скоростей обучения и импульса. Динамика скорости обучения
Первым шагом является разработка функции, которая будет создавать выборки из задачи и разделять их на обучающие и тестовые наборы данных. Кроме того, мы также должны один раз закодировать целевую переменную, чтобы мы могли разработать модель, которая предсказывает вероятность того, что пример принадлежит каждому классу.

При выполнении примера создается одна фигура, содержащая восемь линейных графиков для восьми различных оцененных скоростей обучения. Точность классификации в обучающем наборе данных отмечена синим цветом, тогда как точность в тестовом наборе данных отмечена оранжевым цветом.
Примечание. Ваши результаты могут отличаться из-за стохастического характера алгоритма или процедуры оценки, а также из-за различий в численной точности. Попробуйте запустить пример несколько раз и сравните средний результат.
На графиках показаны колебания поведения при слишком большой скорости обучения 1,0 и неспособность модели чему-либо научиться при слишком маленькой скорости обучения 1E-6 и 1E-7.Мы видим, что модель смогла хорошо изучить проблему со скоростями обучения 1E-1, 1E-2 и 1E-3, хотя последовательно медленнее, поскольку скорость обучения уменьшалась. При выбранной конфигурации модели результаты показывают, что умеренная скорость обучения, равная 0,1, приводит к хорошей производительности модели на обучающих и тестовых наборах.
=====================================
Импульсная динамика
Импульс может сгладить прогресс алгоритма обучения, что, в свою очередь, может ускорить процесс обучения.
Мы можем адаптировать пример из предыдущего раздела, чтобы оценить влияние импульса с фиксированной скоростью обучения. В этом случае мы выберем скорость обучения 0,01, которая в предыдущем разделе сходилась к разумному решению, но потребовала больше эпох, чем скорость обучения 0,1. Функцию fit_model() можно обновить, чтобы она принимала аргумент «импульс» вместо аргумента скорости обучения, который можно использовать в конфигурации класса SGD и сообщать о результирующем графике.

Выполнение примера создает единую фигуру, содержащую четыре линейных графика для различных оцененных значений импульса. Точность классификации в обучающем наборе данных отмечена синим цветом, тогда как точность в тестовом наборе данных отмечена оранжевым цветом. Мы видим, что добавление импульса действительно ускоряет обучение модели. В частности, значения импульса 0,9 и 0,99 обеспечивают приемлемую точность обучения и тестирования примерно в течение 50 периодов обучения, в отличие от 200 периодов обучения, когда импульс не используется. Во всех случаях, когда используется импульс, точность модели на тестовом наборе данных удержания оказывается более стабильной, демонстрируя меньшую волатильность в течение эпох обучения.
=============================
Влияние графиков скорости обучения
В этом разделе мы рассмотрим два графика скорости обучения.
Первый — это затухание, встроенное в класс SGD, а второй — обратный вызов ReduceLROnPlateau. Затухание скорости обучения. Класс SGD предоставляет аргумент «затухание», который определяет затухание скорости обучения.
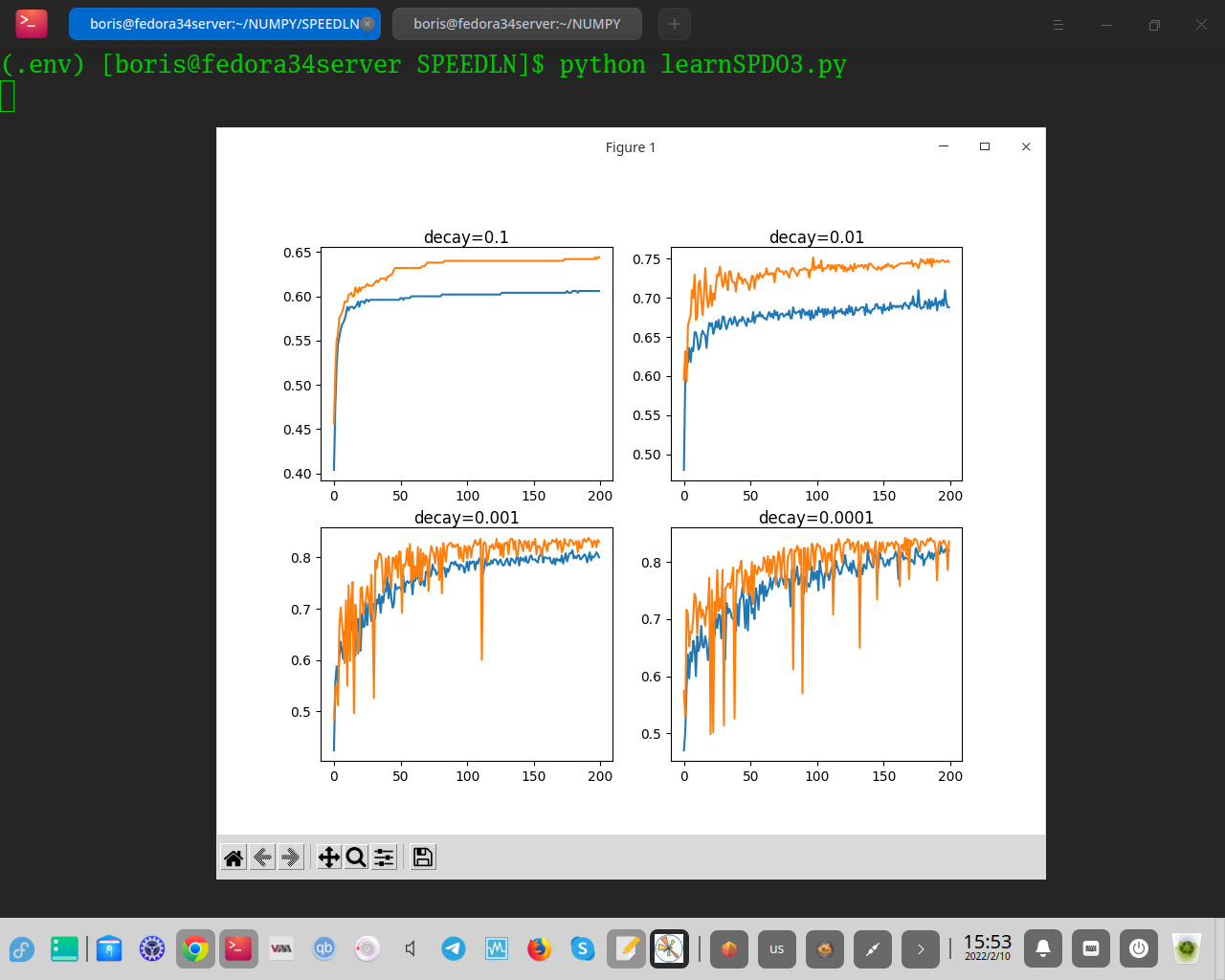
Выполнение примера создает единую фигуру, содержащую четыре линейных графика для различных оцененных значений затухания скорости обучения. Точность классификации в обучающем наборе данных отмечена синим цветом, тогда как точность в тестовом наборе данных отмечена оранжевым цветом.
Примечание. Ваши результаты могут отличаться из-за стохастического характера алгоритма или процедуры оценки, а также из-за различий в численной точности. Попробуйте запустить пример несколько раз и сравните средний результат.
Мы видим, что большие значения затухания 1E-1 и 1E-2 действительно слишком быстро снижают скорость обучения для этой модели по этой проблеме и приводят к низкой производительности. Меньшие значения затухания действительно приводят к лучшей производительности, а значение 1E-4, возможно, приводит к тому же результату, что и полное отсутствие затухания. На самом деле, мы можем рассчитать окончательную скорость обучения с затуханием 1E-4 примерно до 0,0075, что лишь немного меньше начального значения 0,01.
=============================
Снижение скорости обучения на плато
ReduceLROnPlateau снизит скорость обучения в несколько раз после того, как отслеживаемая метрика не изменится в течение заданного количества эпох. Мы можем исследовать влияние различных значений «терпения», то есть количества эпох ожидания изменения, прежде чем снизить скорость обучения. Мы будем использовать скорость обучения по умолчанию 0,01 и снизим скорость обучения на порядок, установив аргумент «коэффициент» равным 0,1.
rlrp = ReduceLROnPlateau (монитор = 'val_loss', фактор = 0,1, терпение = терпение, min_delta = 1E-7)
Будет интересно рассмотреть влияние на скорость обучения в течение эпох обучения. Мы можем сделать это, создав новый обратный вызов Keras, который отвечает за запись скорости обучения в конце каждой эпохи обучения. Затем мы можем получить записанные скорости обучения и построить линейный график, чтобы увидеть, как падения повлияли на скорость обучения. Мы можем создать собственный обратный вызов под названием LearningRateMonitor. Функция on_train_begin() вызывается в начале обучения, и в ней мы можем определить пустой список скоростей обучения. Функция on_epoch_end() вызывается в конце каждой эпохи обучения, и в ней мы можем получить оптимизатор и текущую скорость обучения от оптимизатора и сохранить их в списке. Полный обратный вызов LearningRateMonitor приведен ниже.

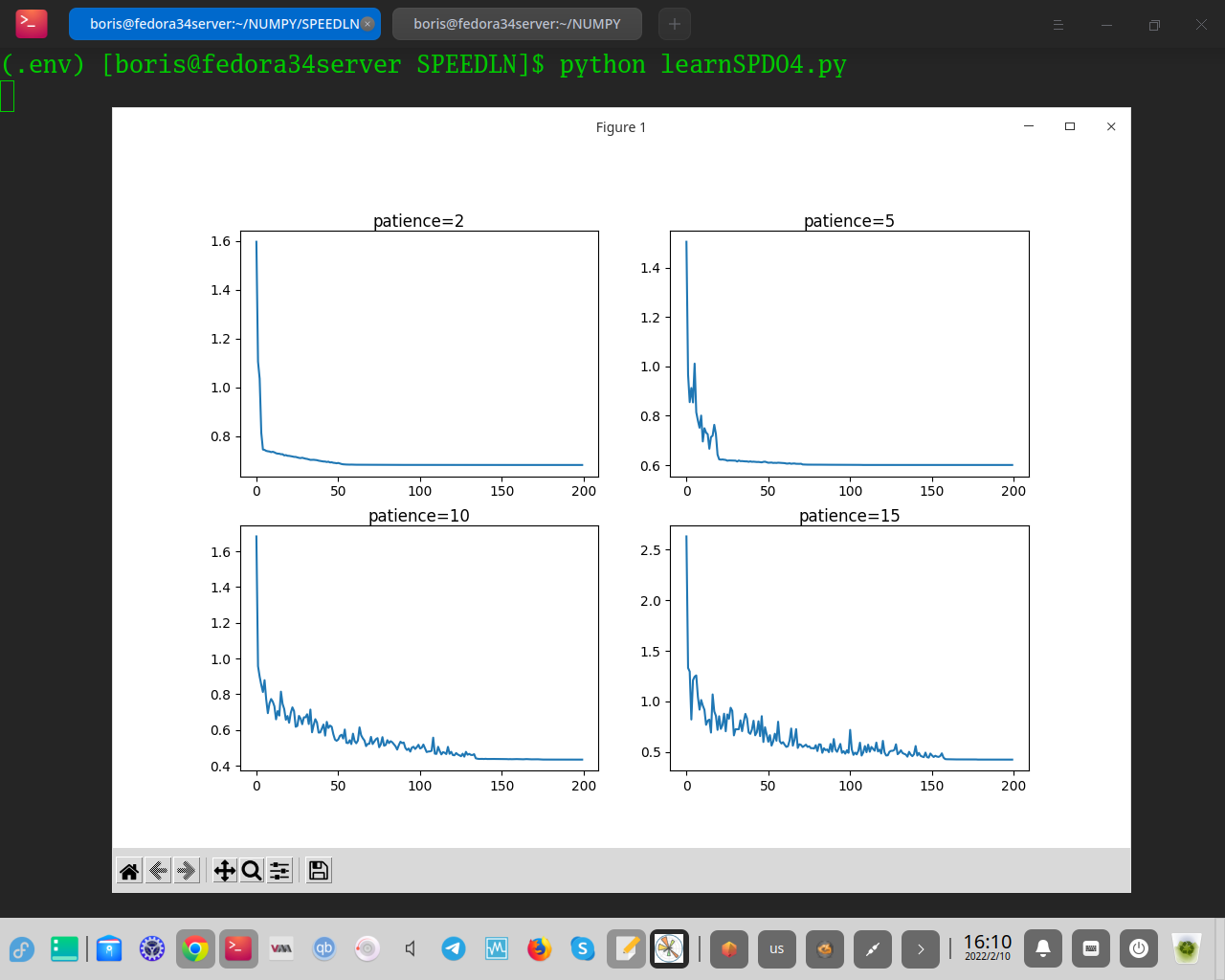
На последнем рисунке показана точность тренировочного набора в течение тренировочных эпох для каждого значения терпения.
Мы можем видеть, что действительно небольшие значения терпения 2 и 5 эпох приводят к преждевременной сходимости модели к неоптимальной модели с точностью около 65% и менее 75% соответственно. Более высокие значения терпения приводят к более производительным моделям: терпение 10 показывает сходимость непосредственно перед 150 эпохами, тогда как терпение 15 продолжает демонстрировать влияние изменчивой точности, учитывая почти полностью неизменную скорость обучения.
Эти графики показывают, как скорость обучения, которая уменьшается разумным образом для проблемы и выбранной конфигурации модели, может привести как к квалифицированному, так и к конвергентному стабильному набору конечных весов, что является желательным свойством в окончательной модели в конце тренировочного прогона.

Эффект адаптивных скоростей обучения
Скорость обучения и графики скорости обучения сложны в настройке и имеют решающее значение для производительности модели нейронной сети с глубоким обучением. Keras предоставляет ряд различных популярных вариантов стохастического градиентного спуска с адаптивной скоростью обучения, таких как:
1.Адаптивный градиентный алгоритм (AdaGrad).
2.Среднеквадратичное распространение (RMSprop).
3.Адаптивная оценка момента (Адам).
Каждый из них предоставляет различную методологию адаптации скорости обучения для каждого веса в сети. Не существует единственного лучшего алгоритма, и результаты алгоритмов гоночной оптимизации для одной задачи вряд ли можно будет перенести на новые задачи. Мы можем изучить динамику различных методов адаптивной скорости обучения в задаче о каплях. Функцию fit_model() можно обновить, чтобы она брала имя алгоритма оптимизации для оценки, которое можно указать в аргументе «оптимизатор» при компиляции модели MLP. Затем будут использоваться параметры по умолчанию для каждого метода. Обновленная версия функции указана ниже.
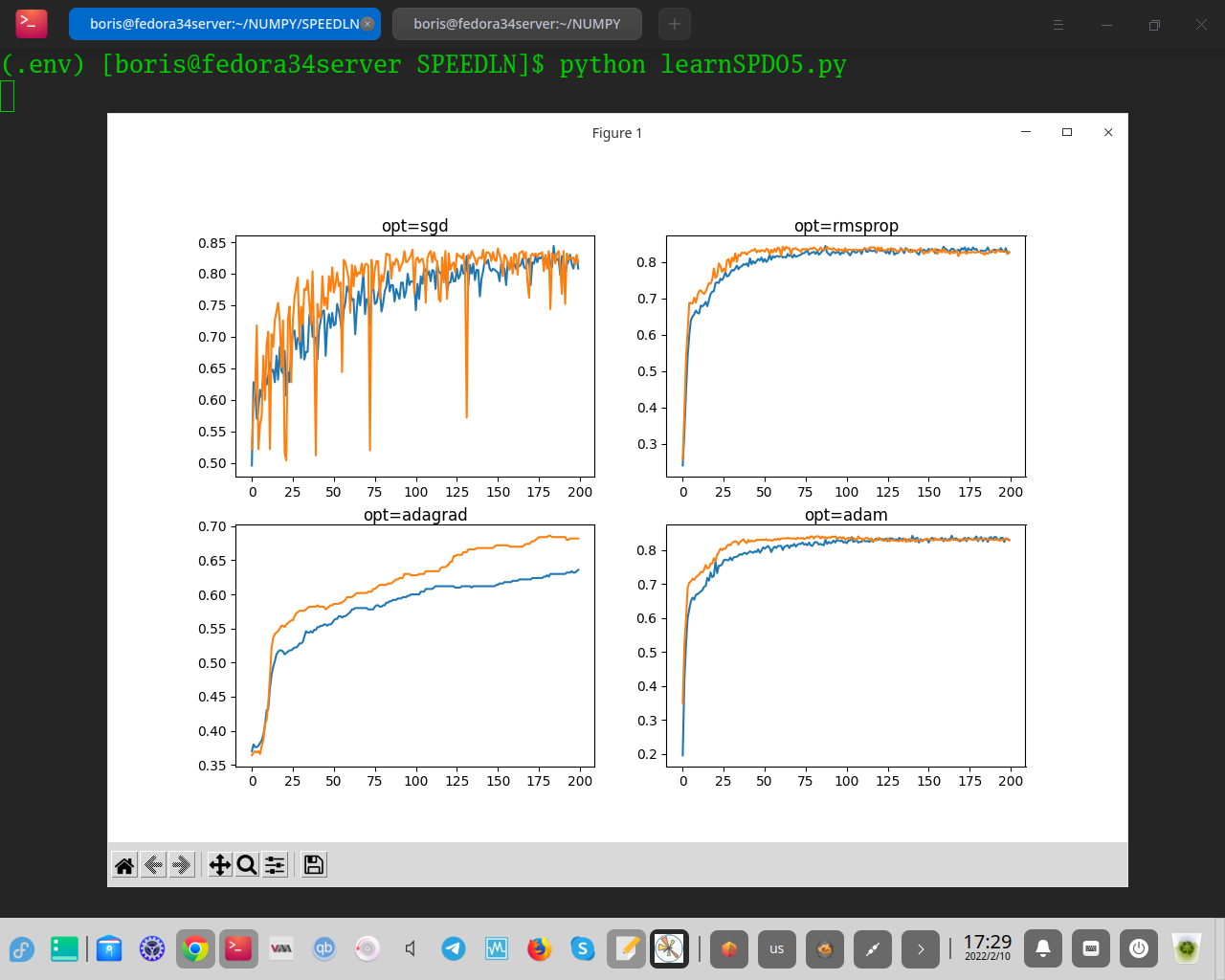
При выполнении примера создается один рисунок, содержащий четыре линейных графика для различных оцениваемых алгоритмов оптимизации. Точность классификации в обучающем наборе данных отмечена синим цветом, тогда как точность в тестовом наборе данных отмечена оранжевым цветом.
Опять же, мы видим, что SGD со скоростью обучения по умолчанию, равной 0,01, и отсутствием импульса действительно изучает проблему, но требует почти всех 200 эпох и приводит к изменчивой точности в обучающих данных и гораздо больше в наборе тестовых данных. Графики показывают, что все три метода адаптивной скорости обучения изучают проблему быстрее и с гораздо меньшей волатильностью в точности обучения и набора тестов. RMSProp, и Адам демонстрируют одинаковую производительность, эффективно изучая проблему в течение 50 эпох обучения и тратя оставшееся время обучения на очень незначительные обновления веса, но не сходясь, как мы видели с графиками скорости обучения в предыдущем разделе.
Читал читал .... И приуныл на третьей странице текста ... Выражайтесь Русским языком. Краткость сестра таланта..... Читать дальше
Занимаюсь развитием Мировоззрения . Работал в радиоастрономии и в области биосферно-кос... · 21 февр 2022
Ничего хорошего не получится. Человек - сложная структура, поэтому ускорение развития интеллекта неизбежно отразится на развитии тела. Конечно это грубая картина, но в реальности есть и другие системы, участвующие в процессе. Грубо говоря, человека можно геометрически сравнить с пирамидой и сразу будет видна проблема с основанием при заметным "утяжелением вершины"... Читать далее
Вопрос находится в группе "Машинное обучение".
Так что речь точно не о людях)
Так что речь точно не о людях)
Ответы на похожие вопросы
Что произойдет, если мы воспользуемся чрезмерной скоростью обучения? — 1 ответ, задан
Ничего. Наш мозг не способен обрабатывать черезмерный объём данных. Самостоятельно вычленяя важное 90-95%данных не усвоиться и будет стёрта из за вновь поступающей. Такова уж наша природа. Мозг сам себя оберегает от перегрузок, но не могу исключать нежелательных последствий. Начиная от повышения температуры до обморока или комы при перегрузках. Наш мозг можно ассоциировать с математической задачей. За N количество времени, способен запомнить J количество данных. +Необходимое время для усвоения материала+ постоянные примеры для поддержания этих данных в активном состоянии.
Мы можем прочитать учебник по физике, химии,географии за 1 день, но через 3 не вспомним ни одной формулы или темы. Если не верите проверьте )
Мы можем прочитать учебник по физике, химии,географии за 1 день, но через 3 не вспомним ни одной формулы или темы. Если не верите проверьте )