Какая функция потерь используется в SVM, а какая в логистической регрессии?
ПрограммированиеМашинное обучение+3
Анонимный вопросМашинное обучение и Нейронные сети
· 1,3 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 22 июн 2022
Потери на петлях — это особый тип функции стоимости, который включает запас или расстояние от границы классификации в расчет стоимости. Даже если новые наблюдения классифицируются правильно, они могут повлечь за собой штраф, если отступ от границы решения недостаточно велик. Потери вращения увеличиваются линейно.
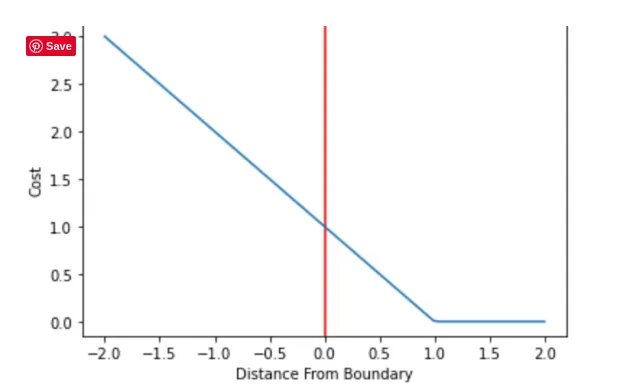
Будучи знакомы с построением гиперплоскостей и их полей в машинах опорных векторов, вы известно , что поля часто определяются как расстояние, равное 1, от гиперплоскости, разделяющей данные. Нужно, чтобы точки данных не только попадали на правильную сторону гиперплоскости, но и располагались за ее пределами.
Машины опорных векторов решают проблему классификации, когда наблюдения имеют результат +1 или -1. Машина опорных векторов выдает действительный результат, отрицательный или положительный, в зависимости от того, на какую сторону границы решения он попадает. Только в том случае, если наблюдение классифицировано правильно и расстояние от плоскости больше допустимого, оно не будет подвергаться штрафу. Расстояние от гиперплоскости можно рассматривать как меру доверия. Чем дальше наблюдение от плоскости, тем увереннее оно в классификации.
Например, если наблюдение было связано с фактическим результатом +1 , а SVM выдал результат 1,5, потеря будет равна 0.
В отличие от таких методов, как линейная регрессия, когда мы пытаемся найти линию, которая минимизирует расстояние от точек данных,
"SVM пытается максимизировать расстояние"
====================================
Перейдем к логистической регрессии. Это контролируемый алгоритм машинного обучения, который используется для решения задач классификации (например, для определения того, является ли письмо спамом или нет, для проверки наличия или отсутствия кота на изображении). Логистическая регрессия в отличии от линейной регрессии, имеет два существенных отличия.
(1) Она использует сигмовидную функцию активации выходного нейрона, чтобы сжать вывод в диапазоне
0–1 (чтобы представить вывод как вероятность).
(2) Она использует функцию потерь, называемую потерей журнала, для расчета ошибки. Среди двух вышеупомянутых пунктов первый пункт прост и интуитивно понятен, поскольку нам нужно, чтобы результат находился в диапазоне 0–1 для задач классификации.
В случае логистической регрессии мы используем новую функцию потерь, называемую логарифмическими потерями, вместо MSE.
Уравнение функции логарифмических потерь "Log loss function" имеет вид:

у - реальный выход, р - вероятность , предсказанная логистической регрессией.