Какие критерии информативности используются при синтезе решающего дерева и почему?
Машинное обучениеАлгоритмы+3
Анонимный вопросМашинное обучение и Нейронные сети
· 2,5 K
При построении вершины для решающего дерева мы максимизируем функционал:
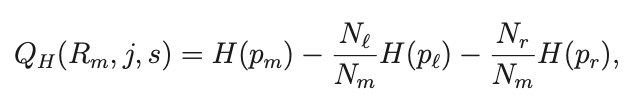
по j — признак, s - порог разбиения.
N_l, N_r — количество объектов в левой и правой частях после разбиения по выбранному предикату, а N_m количество объект до разбиения.
Это и есть критерий информативности по его сути, так как уменьшает хаотичность двух вершин после разбиения(r — правой, l — левой).
Выбор начинается на этапе определения этого самого критерия хаотичности(impurity criterion).
Для регрессии это самый обычные MSE:
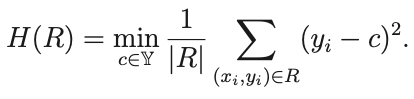
Конечно мы знаем, что минимум этого выражения достигается на среднем значении целевой переменной. То есть c равняется среднему y_i внутри этой вершины.
Для классификации есть два наиболее популярных:
Критерий Джинни:
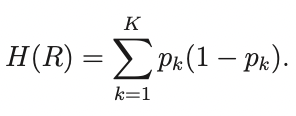
Энтропийный критерий:
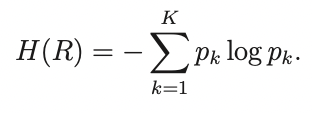
Каких то правил и эвристик для выбора одного из этих двух критериев нет и если необходимо выбрать, есть хороший способ — кроссвалидация.
1 эксперт согласен
Борис Державец
14 июля 2022подтверждает
Сравните с одним из других ответов на этот же вопрос
https://yandex.ru/q/tech/12214890753/?answer_id=5313a41d-e23c-... Читать дальше
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 14 июл 2022
Дерево решений — это контролируемый алгоритм обучения, используемый как для задач классификации, так и для задач регрессии. Проще говоря, он принимает форму дерева с ветвями, представляющими возможные ответы на заданный вопрос. Существуют метрики, используемые для обучения деревьев решений. Одним из них является получение информации
Можно определить прирост информации... Читать далее
Во время построения решающего дерева необходимо задание такого критерия, как функционал качества, на основе которого осуществляется разбиение выборки на каждом шаге. С этой целью обозначение идет через Rm 4 множество объектов, попавших в вершину, разбиваемую на данном шаге, а через Rℓ и Rr — объекты, попадающие в левое и правое поддерево соответственно при заданном... Читать далее