Как вывести градиентный метод обучения в логистической регрессии?
ПрограммированиеМашинное обучение+3
Анонимный вопросМашинное обучение и Нейронные сети
· 1,4 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 2 сент 2022
Добавлено 03.09.22 14:55 МСК
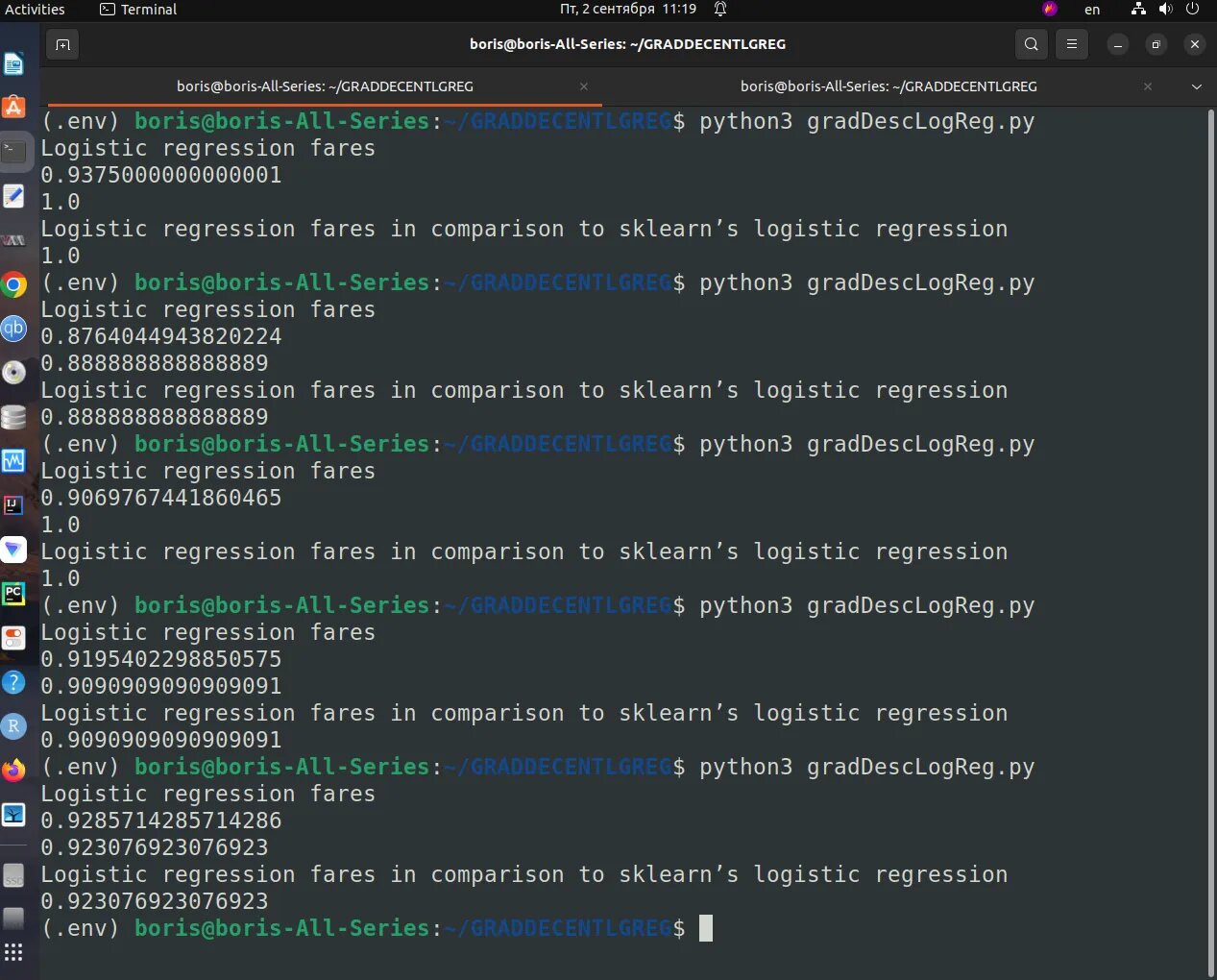
В тот же код добавлен плот убывания функции Cost(i) когда i => iter, плоттинг внесен в функцию fit(self,X,y,alpha=0.001,iter=400).
Смотри как изменения в fit(…), описанные после первой версии. plt.draw() внесен в fit(…), plt.show() выполнен после печати результатов.

Изменения добавлены в https://informatics-ege.blogspot.com/2022/09/implementing-logistic-regression-from.html
============================================
Функция стоимости или функция потерь — это та функция, которая описывает, насколько расчетное значение отклоняется от фактического значения. Линейная регрессия использует наименьший квадрат ошибки в качестве функции стоимости. Но функция наименьших квадратов ошибок для логистической регрессии невыпукла. При выполнении градиентного спуска шансов, что мы застрянем в локальном минимуме, больше. Поэтому вместо этого мы используем логарифмическую потерю в качестве функции стоимости.

h(x) = is the sigmoid function
Градиентный спуск
Следующий шаг — градиентный спуск. Градиентный спуск — это алгоритм оптимизации, который отвечает за изучение наиболее подходящих параметров. Градиенты представляют собой вектор производной
1-го порядка функции стоимости. Это направление наискорейшего подъема или максимума функции. Для градиентного спуска мы движемся в направлении, противоположном градиентам. Мы будем обновлять веса на каждой итерации до сходимости.
Дифференцируя функцию стоимости, мы получаем выражение градиентного спуска
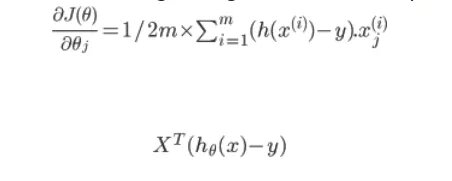
Последняя формула равносильна первой и будет использована в коде
def fit(self,X,y,alpha=0.001,iter=400)
Далее код на Пайтон смотри https://informatics-ege.blogspot.com/2022/09/implementing-logistic-regression-from.html