Мы запустили новый поисковый алгоритм — «Палех». Он позволяет поиску Яндекса точнее понимать, о чём его спрашивают люди. Благодаря «Палеху» поиск лучше находит веб-страницы, которые соответствуют запросам не только по ключевым словам, но и по смыслу. За сопоставление смысла запросов и документов отвечает поисковая модель на основе нейронных сетей.
«Длинный хвост»
Каждый день поиск Яндекса отвечает примерно на 280 миллионов запросов. Какие-то из них, например [вконтакте], люди вводят в поисковую строку практически каждую секунду. Какие-то запросы уникальны — их задают один раз, и они, возможно, больше никогда не повторятся. Уникальных и просто редких запросов очень много — около ста миллионов в день.
График частотного распределения запросов в Яндексе часто представляют в виде птицы, у которой есть клюв, туловище и длинный хвост. Список самых распространённых запросов не особо велик, но их задают очень-очень часто — это «клюв» птички. Запросы средней частотности образуют «туловище». Низкочастотные запросы по отдельности встречаются чрезвычайно редко, но вместе составляют существенную часть поискового потока и поэтому складываются в «длинный хвост».
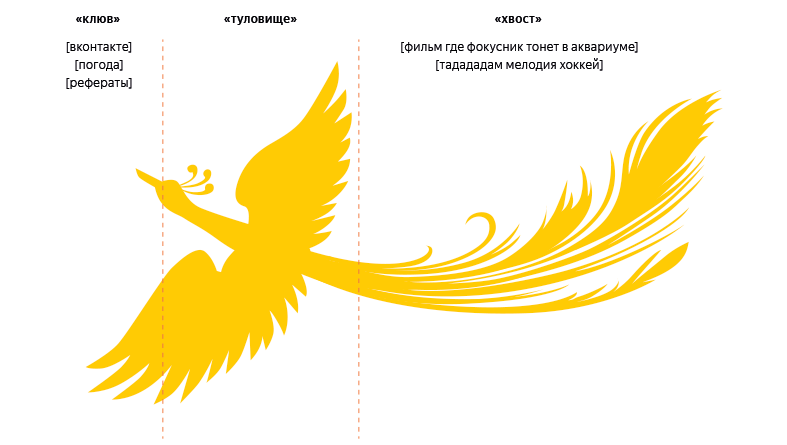 Новый алгоритм позволяет поиску Яндекса лучше отвечать на сложные запросы из «длинного хвоста». Такой хвост есть у сказочной Жар-птицы, которая часто появляется на палехской миниатюре. Поэтому мы дали алгоритму название «Палех».
Новый алгоритм позволяет поиску Яндекса лучше отвечать на сложные запросы из «длинного хвоста». Такой хвост есть у сказочной Жар-птицы, которая часто появляется на палехской миниатюре. Поэтому мы дали алгоритму название «Палех».
Запросы из «длинного хвоста» очень разнообразны, но среди них можно выделить несколько групп. Например, одна из них — запросы от детей, которые пока не освоили язык общения с поиском и часто обращаются к нему как к живому собеседнику: [дорогой яндекс посоветуй пожалуйста новые интересные игры про фей для плантика]. Ещё одна группа — запросы от людей, которые хотят узнать название фильма или книги по запомнившемуся эпизоду: [фильм про человека который выращивал картошку на другой планете] («Марсианин») или [фильм где физики рассказывали даме про дейтерий] («Девять дней одного года»).
Особенность запросов из «длинного хвоста» в том, что обычно они более сложны для поисковой системы. Запросы из «клюва» задают многократно, и для них есть масса разнообразной пользовательской статистики. Чем больше знаний о запросах, страницах и действиях пользователей накопил поиск, тем лучше он находит релевантные результаты. В случае с редкими запросами поведенческой статистики может не быть — а значит, Яндексу гораздо труднее понять, какие сайты хорошо подходят для ответа, а какие не очень. Задача осложняется тем, что далеко не всегда на релевантной страничке встречаются слова из запроса — ведь один и тот же смысл в запросе и на странице может быть выражен совершенно по-разному.
Несмотря на то, что каждый из запросов «длинного хвоста» по отдельности встречается крайне редко, мы всё равно хотим находить по ним хорошие результаты. К решению этой задачи мы привлекли нейронные сети.
Семантический вектор
Искусственные нейронные сети — один из методов машинного обучения, который стал особенно популярен в последние годы. Нейросети показывают отличные результаты в анализе естественной информации: картинок, звука, текста. Например, нейронную сеть можно обучить распознавать на изображениях те или иные объекты — скажем, деревья или собак. В ходе обучения ей показывают огромное количество картинок, где есть нужные объекты (положительные примеры) и где их нет (отрицательные примеры). В результате нейросеть получает способность верно определять нужные объекты на любых изображениях.
В нашем случае мы имеем дело не с картинками, а с текстами — это тексты поисковых запросов и заголовков веб-страниц, — но обучение проходит по той же схеме: на положительных и отрицательных примерах. Каждый пример — это пара «запрос — заголовок». Подобрать примеры можно с помощью накопленной поиском статистики. Обучаясь на поведении пользователей, нейросеть начинает «понимать» смысловое соответствие между запросом и заголовками страниц.
Компьютеру проще работать с числами, чем с буквами, поэтому поиск соответствий между запросами и веб-страницами сводится к сравнению чисел. Мы научили нейронную сеть переводить миллиарды известных Яндексу заголовков веб-страниц в числа — а точнее, в группы из трёхсот чисел каждая. В результате все документы из базы данных Яндекса получили координаты в трёхсотмерном пространстве.
Вообразить такую систему координат человеку довольно трудно. Давайте упростим задачу и представим, что каждой веб-странице соответствует группа не из трёхсот, а из двух чисел — и мы имеем дело не с трёхсотмерным, а всего лишь с двумерным пространством. Тогда получится, что каждое число — это определённая координата по одной из двух осей, а каждая веб-страница просто соответствует точке на двумерной координатной плоскости.
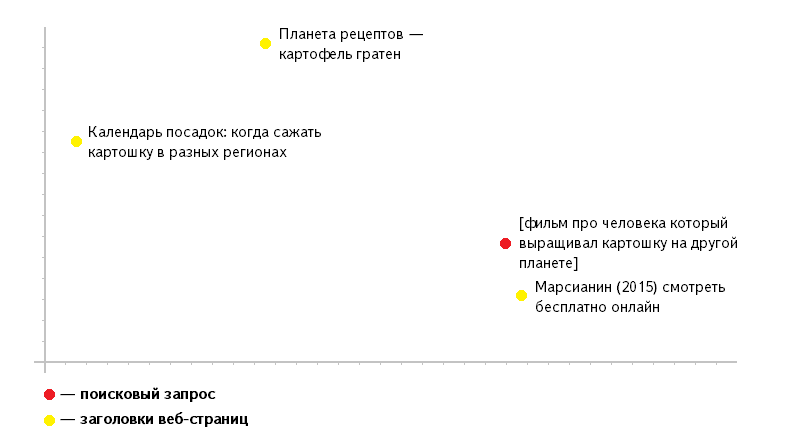
Точно так же в набор чисел можно перевести и текст поискового запроса. Другими словами, мы можем разместить запрос в том же пространстве координат, что и веб-страницу. Замечательное свойство такого представления состоит в том, что чем ближе они будут расположены друг к другу, тем лучше страница отвечает на запрос.
Такой способ обработки запроса и его сопоставления с вероятными ответами мы назвали семантическим вектором. Этот подход хорошо работает в тех случаях, когда запрос относится к области «длинного хвоста». Семантические векторы позволяют нам лучше находить ответы на сложные низкочастотные запросы, по которым имеется слишком мало пользовательской статистики. Более того, представляя запрос и веб-страницу в виде вектора в трёхсотмерном пространстве, мы можем понять, что они хорошо соответствуют друг другу, даже если у них нет ни одного общего слова.
Мы начали использовать семантический вектор несколько месяцев назад, постепенно развивая и улучшая лежащие в его основе нейронные модели. О том, как мы обучали нейронную сеть преобразовывать запросы и документы в семантические векторы, читайте в блоге Яндекса на «Хабрахабре».
Дальше — больше
Семантический вектор применяется не только в поиске Яндекса, но и в других сервисах — например, в Картинках. Там он помогает находить в интернете изображения, которые наиболее точно соответствуют текстовому запросу.
Технология семантических векторов обладает огромным потенциалом. Например, переводить в такие векторы можно не только заголовки, но и полные тексты документов — это позволит ещё точнее сопоставлять запросы и веб-страницы. В виде семантического вектора можно представить и профиль пользователя в интернете — то есть его интересы, предыдущие поисковые запросы, переходы по ссылкам. Далёкая, но чрезвычайно интересная цель состоит в том, чтобы получить на основе нейронных сетей модели, способные «понимать» семантическое соответствие запросов и документов на уровне, сравнимом с уровнем человека.