
Два года назад мы открыли Yandex Data Factory. Это подразделение Яндекса, которое помогает другим компаниям решать задачи с помощью технологий обработки и анализа данных. С «большими данными» имеют дело во всех отраслях — от телекоммуникаций до дорожного хозяйства. Сегодня мы расскажем о проекте, над которым Yandex Data Factory работает вместе с фармацевтической компанией «АстраЗенека».
В число лекарств, выпускаемых компанией, входят антибиотики — препараты, которые используются для лечения бактериальных инфекций. Правильно подобранный антибиотик подавляет рост и размножение «плохих» бактерий, которые вызывают инфекционные заболевания. Антибиотики позволили лечить многие заболевания, ранее считавшиеся смертельными, — чуму, холеру, туберкулёз.
Устойчивость к антибиотикам
Бактерии, на которые воздействуют антибиотики, — живые существа, которые имеют свойство приспосабливаться к меняющимся условиям. Со временем штаммы «плохих» бактерий могут научиться противостоять препарату — и тогда лекарство, которое много лет помогало в борьбе с той или иной инфекцией, внезапно перестаёт работать. Этот феномен называется устойчивостью, или резистентностью, к антибиотикам.
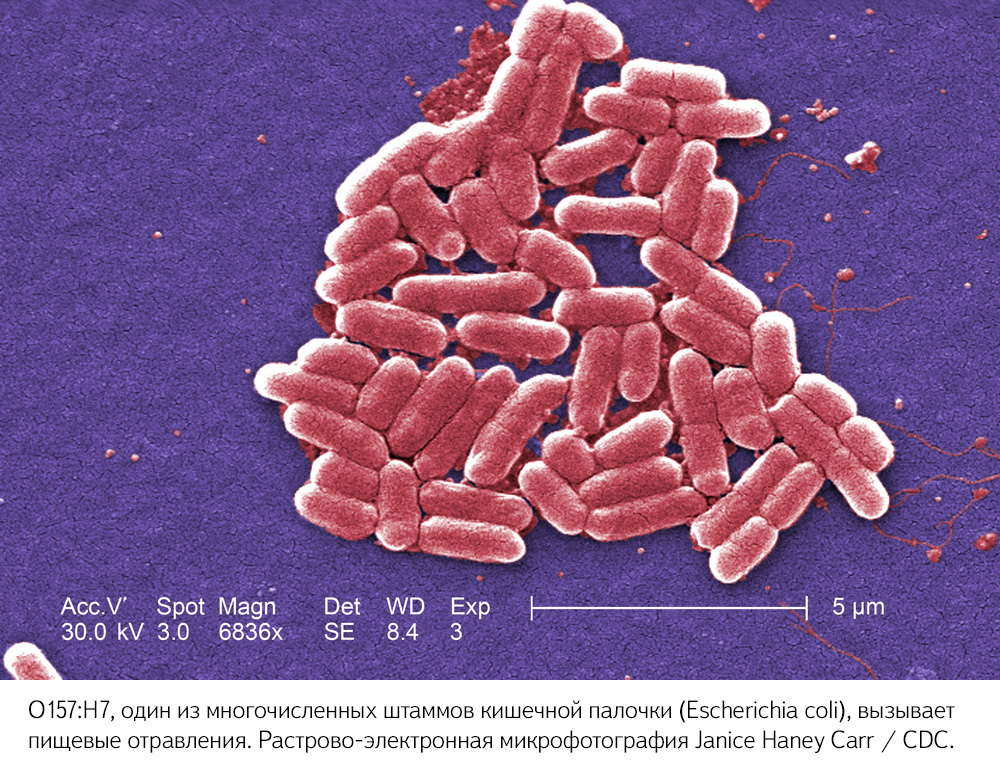
Попытка лечить человека средством, которое не оказывает никакого воздействия, может привести к печальным последствиям. К тому же при подборе антибиотиков медлить нельзя. Во многих случаях — например, при септическом шоке, — успех лечения напрямую зависит от того, как быстро пациент получил эффективное лекарство. Ежегодно из-за резистентности к антибактериальным препаратам в мире умирают сотни тысяч человек, и по некоторым оценкам, к 2050 году количество летальных исходов может возрасти до 10 миллионов.
Поисковый сервис
Теме резистентности к антибиотикам посвящено много научных работ, и каждый год появляются труды с новой информацией. «АстраЗенека» задалась целью объединить результаты наблюдений, сделанных в разных регионах России, в единую базу данных. Такая база помогла бы врачам подбирать наиболее эффективную терапию, а учёным — отслеживать динамику показателей, чтобы лучше изучить само явление резистентности к антибиотикам. В мире подобные базы уже существуют — например, это EARS-Net в Европе и NARMS в США.
Многие научные работы, вне зависимости от того, где и когда они вышли, рано или поздно публикуются в свободном доступе в интернете. В Yandex Data Factory разработали для компании «АстраЗенека» поисковый сервис, который находит в сети труды на русском языке с нужными для пополнения базы сведениями. Планируется, что сервис станет частью большой информационно-справочной системы для врачей и работников фармпромышленности.
Требования к документам
Чтобы данные из найденной в интернете научной работы можно было занести в базу, она должна отвечать определённым требованиям. Они касаются как содержания, так и структуры. Необходимо, чтобы основной темой исследования была резистентность к антибиотикам. Работа должна быть самостоятельной — не подходят, например, обзорные публикации, клинические рекомендации или статьи по проблемам лечения инфекционных заболеваний. В работе обязательно должны упоминаться задействованные в исследовании методы и материалы. Наконец, работа может быть доступна как в виде отдельного документа, так и в составе сборника статей — это тоже требуется учитывать при поиске.
Модель релевантности
В основе любого поисковика лежит модель релевантности — её ещё называют поисковой моделью. Она оценивает, насколько тот или иной документ соответствует поисковому запросу. Из-за специфических требований к документам использовать модель, которая задействована в обычном поиске Яндекса, было нельзя, поэтому мы разработали новую.
В модели, которую создали в Yandex Data Factory, поиск работ проходит в два этапа. На первом этапе из гигантского множества известных Яндексу документов система выделяет те, которые содержат правильные комбинации ключевых слов — в большинстве своём это названия бактерий и антибиотиков. В результате получается список документов, которые предварительно подходят на роль релевантных. Таких документов оказалось очень много, около 60 тысяч.
Далее найденные документы ранжируются. Системе нужно оценить, насколько каждый из них соответствует требованиям, и упорядочить по степени соответствия. Для решения этой задачи плохо подходят признаки наподобие ключевых слов. Если опираться только на них, система может посчитать вполне релевантными и школьный реферат, и статью на научно-популярном сайте. Необходимы более сложные критерии — такие, которыми оперируют сами учёные.

Чтобы научить систему думать как учёный, мы выявили факторы ранжирования — показатели, которые могут влиять на релевантность документа. Такими показателями могут быть, например, концентрация ключевых слов в тех или иных разделах статьи или наличие определённых стоп-слов. Но сами по себе факторы имеют мало значения. Чтобы можно было сказать наверняка, подходит документ или нет, требуется отыскать сложные зависимости между факторами и степенью релевантности документа. Для этого используется машинное обучение.
Машинное обучение тоже проходит в несколько этапов. На каждом из них машине показывают примеры — образцы подходящих и неподходящих документов. Получить примеры нам помогли асессоры — специалисты из «АстраЗенека». Они просматривали небольшие случайные выборки документов и выносили вердикт: релевантны они или нет.
Результаты
Когда обучение было завершено и документы отранжированы, оставалось измерить, насколько удачно модель справилась с задачей. Для этого снова пригодились оценки асессоров.
Оказалось, что из первой тысячи выданных моделью документов релевантными, по оценкам асессоров, являются 579 — то есть нижняя оценка точности поиска составляет 57,9 процента. (Документы, попавшие в первую тысячу, но не рассмотренные асессорами, мы считали нерелевантными.) При этом из абсолютно всех документов, помеченных асессорами как релевантные, в первую тысячу попали 94,8 процента — то есть полнота поиска составляет как минимум 94,8 процента. Для сравнения, когда мы только начинали проект, удовлетворительной было решено считать точность в 20 процентов — то есть результаты, показанные сервисом, превзошли ожидания почти в три раза.
Сейчас поисковый сервис, созданный в Yandex Data Factory, используется для поиска в интернете научных работ об устойчивости к антибиотикам. Однако поисковик по сути является универсальным инструментом. Модель можно обучить на новых документах и использовать сервис в других отраслях — умение обрабатывать сложные данные и извлекать из них пользу может пригодиться не только в фармацевтике.