Какие проблемы пытается решить кросс-валидация? Она эффективна?
ПрограммированиеData science+2
Анонимный вопросData Science
· 1,8 K
Openstack DevOps and IBM/Informix Certified DBA . Phd in Math (Duality of spaces of... · 30 дек 2021
Перекрестная проверка - это метод оценки модели, который лучше, чем остатки. Проблема с остаточными оценками заключается в том, что они не дают указания на то, насколько хорошо обучающийся будет делать, когда его просят сделать новые прогнозы для данных, которые он еще не видел. Один из способов решить эту проблему - не использовать весь набор данных при обучении учащегося. Некоторые данные удаляются перед началом обучения. Затем, когда обучение завершено, удаленные данные можно использовать для тестирования производительности изученной модели на `` новых '' данных. Это основная идея для целого класса методов оценки модели, называемых перекрестной проверкой.
=================
Метод удержания - это простейший вид перекрестной проверки. Набор данных разделен на два набора, которые называются обучающим набором и набором для тестирования. Аппроксиматор функции подходит для функции, использующей только обучающий набор. Затем аппроксиматору функции предлагается предсказать выходные значения для данных в наборе тестирования (он никогда раньше не видел эти выходные значения). Ошибки, которые он делает, накапливаются, как и раньше, чтобы получить среднюю абсолютную ошибку тестового набора, которая используется для оценки модели. Преимущество этого метода заключается в том, что он обычно предпочтительнее остаточного метода и не требует больше времени для вычислений. Однако его оценка может иметь большой разброс. Оценка может сильно зависеть от того, какие точки данных попадают в обучающий набор, а какие - в тестовый, и, таким образом, оценка может значительно отличаться в зависимости от того, как выполняется разделение.
==================
K-кратная перекрестная проверка - один из способов улучшить метод удержания. Набор данных делится на k подмножеств, и метод удержания повторяется k раз. Каждый раз один из k подмножеств используется в качестве тестового набора, а другие k-1 подмножества собираются вместе, чтобы сформировать обучающий набор. Затем вычисляется средняя ошибка по всем k испытаниям. Преимущество этого метода в том, что не так важно, как разделяются данные. Каждая точка данных попадает в тестовый набор ровно один раз и попадает в обучающий набор k-1 раз. Дисперсия полученной оценки уменьшается с увеличением k. Недостатком этого метода является то, что алгоритм обучения необходимо повторно запускать с нуля k раз, что означает, что для выполнения оценки требуется в k раз больше вычислений. Вариант этого метода - случайное разделение данных на тестовую и обучающую выборку k разное количество раз. Преимущество этого заключается в том, что вы можете независимо выбирать, насколько велик каждый набор тестов и сколько испытаний вы усредняете.
==================
Перекрестная проверка с исключением по одному - это К-кратная перекрестная проверка, доведенная до своего логического предела, где K равно N, количеству точек данных в наборе. Это означает, что N раз, аппроксиматор функции обучается на всех данных, кроме одной точки, и для этой точки делается прогноз. Как и раньше, вычисляется средняя ошибка, которая используется для оценки модели. Оценка, полученная с помощью ошибки перекрестной проверки с исключением одного-одного (LOO-XVE), хороша, но при первом проходе ее вычисление кажется очень дорогостоящим. К счастью, учащиеся с локальным взвешиванием могут делать LOO-прогнозы так же легко, как и обычные. Это означает, что вычисление LOO-XVE занимает не больше времени, чем вычисление остаточной ошибки, и это гораздо лучший способ оценки моделей. Вскоре мы увидим, что Vizier в значительной степени полагается на LOO-XVE при выборе своих метакодов.

На рис. 26 показан пример выполнения перекрестной проверки лучше, чем остаточная ошибка. Набор данных на двух верхних графиках представляет собой простую базовую функцию со значительным шумом. Перекрестная проверка говорит нам, что лучше всего широкое сглаживание. Набор данных на двух нижних графиках представляет собой сложную базовую функцию без шума. Перекрестная проверка говорит нам, что для этого набора данных лучше всего очень небольшое сглаживание.
Теперь вернемся к вопросу выбора хорошего метакода для набора данных a1.mbl:
Файл -> Открыть -> a1.mbl
Правка -> Метакод -> A90: 9
Модель -> LOOPredict
Правка -> Метакод -> L90: 9
Модель -> LOOPredict
Правка -> Метакод -> L10: 9
Модель -> LOOPredict
LOOPredict просматривает весь набор данных и делает LOO прогнозы для каждой точки. Внизу страницы отображается сводная статистика, включая среднюю ошибку LOO, ошибку RMS LOO и информацию о точке данных с наибольшей ошибкой. Средние абсолютные значения LOO-XVE для трех метакодов, приведенных выше (те же три, которые использовались для создания графиков на рис. 25), составляют 2,98, 1,23 и 1,80. Эти значения показывают, что глобальная линейная регрессия - лучший метакод из этих трех, что согласуется с нашим интуитивным ощущением при просмотре графиков на рис. 25. Если вы повторите описанную выше операцию с набором данных b1.mbl, вы получите значения 4,83, 4,45 и 0,39, что также согласуется с нашими наблюдениями.
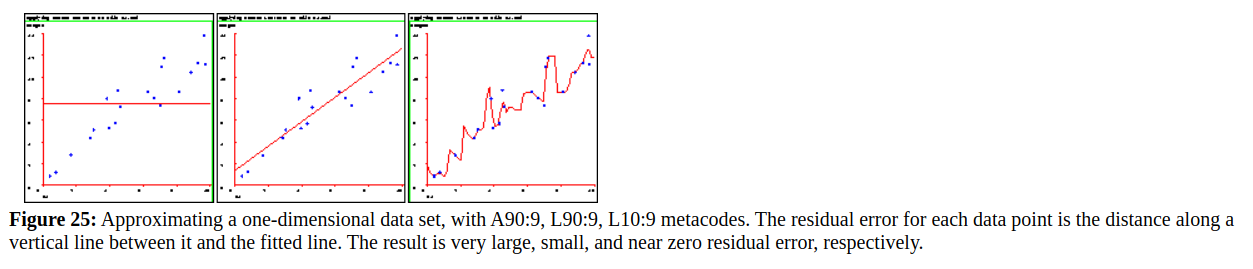
Рисунок 25: Аппроксимация одномерного набора данных с метакодами A90: 9, L90: 9, L10: 9. Остаточная ошибка для каждой точки данных - это расстояние по вертикальной линии между ней и подобранной линией. Результат - очень большая, малая и близкая к нулю остаточная ошибка соответственно.

На рис. 24 показан пример, в котором выбор модели с наименьшей остаточной ошибкой является хорошей идеей (данные поступают из b1.mbl, если вы хотите загрузить их в Vizier). Подгонка справа явно лучше всего подходит для данных из трех, а его средняя абсолютная остаточная ошибка близка к нулю. Однако выбор моделей по остаточной ошибке - дело рискованное.
На рис. 25 показан пример (из a1.mbl), где остатки могут сбить нас с пути. Опять же, остаточная ошибка на среднем графике умеренная, а остаточная ошибка на крайнем правом графике близка к нулю. Хотя средний сюжет подходит гораздо лучше. Причина в том, что крайний правый график соответствует шуму в данных. Это явление называется `` переобучением '' и является распространенной проблемой, которую следует избегать в обучающих системах. Переобучение в этом примере означает, что ошибки в прогнозировании будущих точек данных по этой кривой на самом деле будут выше, чем если бы вместо этого мы использовали подгонку среднего графика. В общем, предпочтительнее использовать что-то более надежное, чем остаточная ошибка, чтобы выбрать хорошую модель и избежать переобучения.